今天刚装好python环境,想要练练手。找了网上的教程敲了一个简单的爬虫代码,下载lofter的图片。
程序思路
(1)锁定目标网站
(2)提取HTML页面代码
(3)findall查找图片url
(4)保存图片
程序步骤
(1)确定目标网站
(2)分析该网页的代码
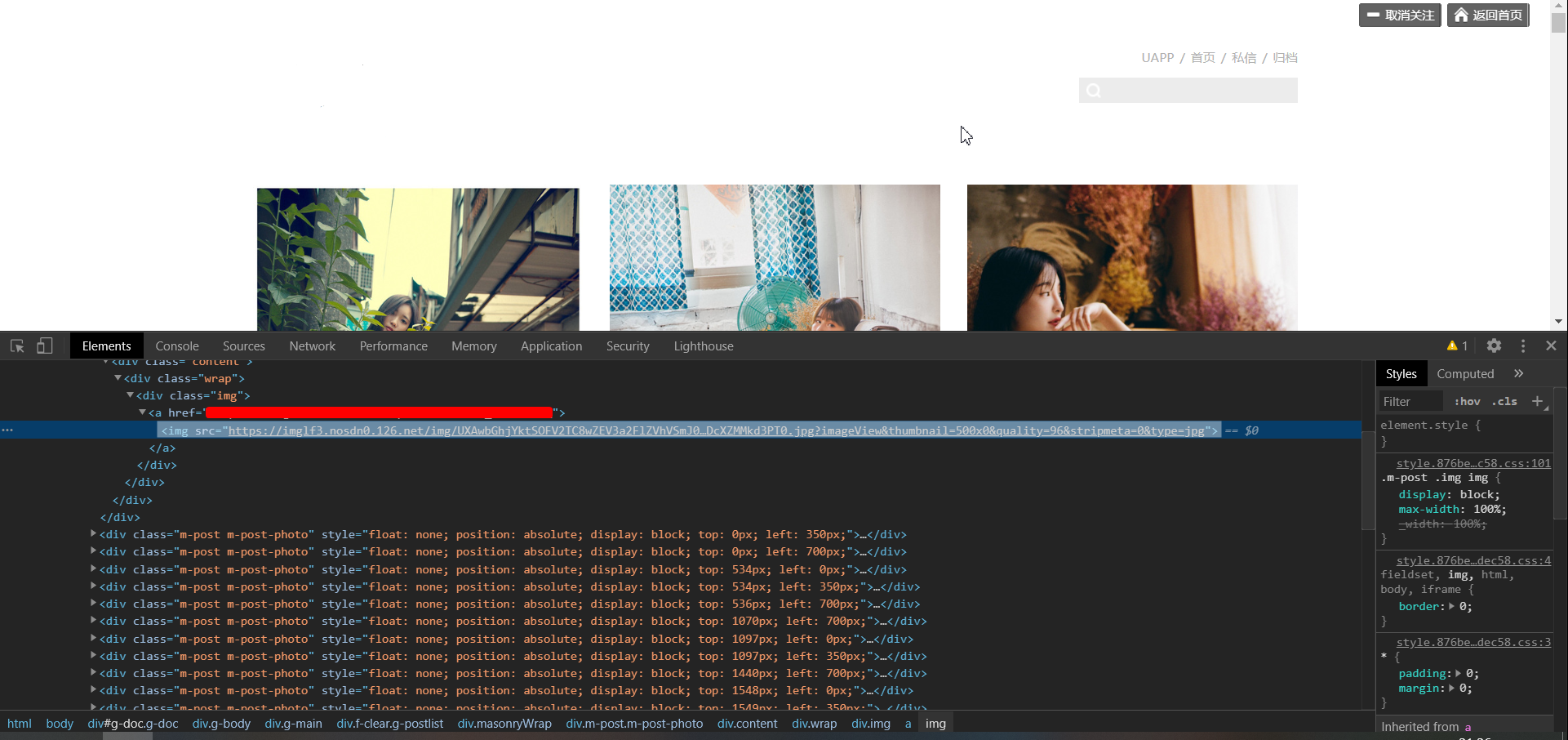
(3)findall查找出所有图片的url,保存到list中
(4)遍历list,保存到本地
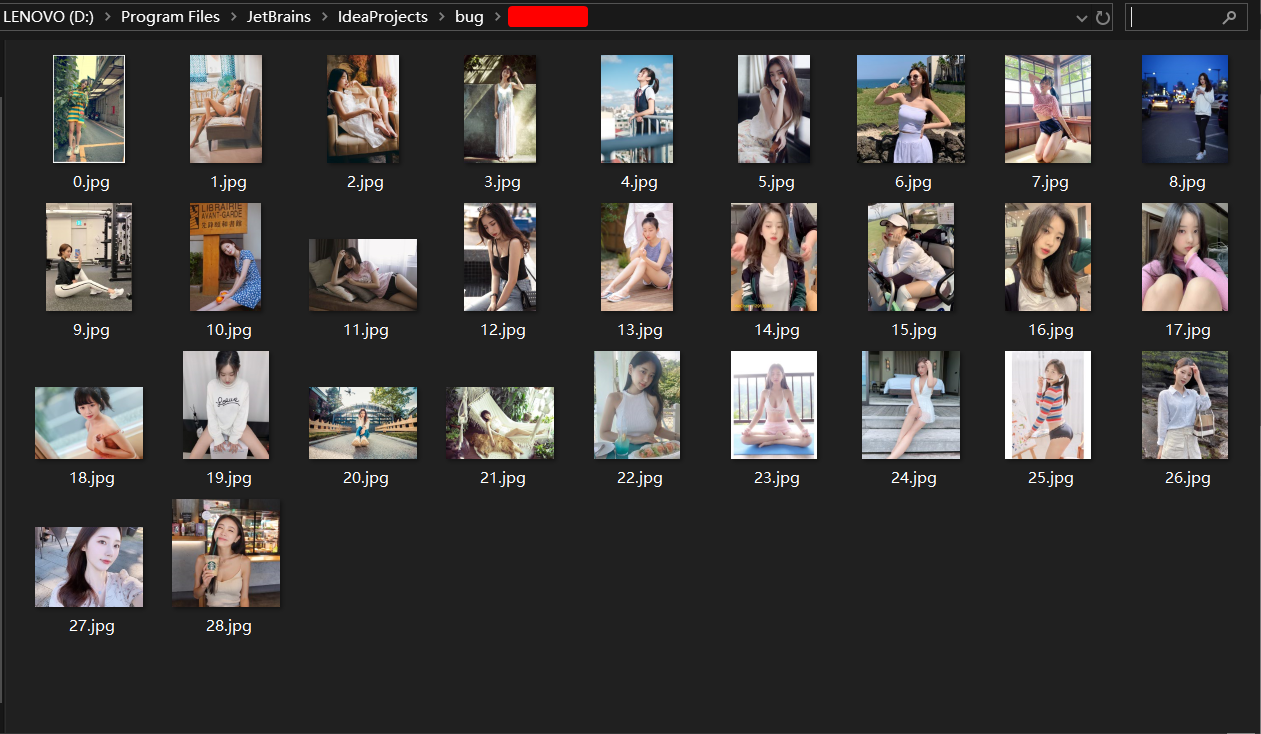
程序源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| """请求网页"""
import time
import requests
import re
import os
"""请求头部"""
headers = {
'User-Agent' : 'lofter'
}
response = requests.get('https://xxx.com/',headers=headers)
html = response.text
"""解析网页"""
dir_name = re.findall('<a class="f-trans" hidefocus="true" href="/">(.*?)</a>',html)[-1]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
urls = re.findall('<img src="(.*?)" />',html)
print(urls)
"""保存图片"""
for i in range(len(urls)):
time.sleep(1)
file_name = str(i)
response = requests.get(urls[i], headers=headers)
with open(dir_name + '/' + file_name + '.jpg','wb') as f:
f.write(response.content)
|
