
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。
1.ES是什么
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。 但是,Lucene只是一个库。想要发挥其强大的作用,你需使用Java并要将其集成到你的应用中。Lucene非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的。
Elasticsearch也是使用Java编写并使用Lucene来建立索引并实现搜索功能,但是它的目的是通过简单连贯的RESTful API让全文搜索变得简单并隐藏Lucene的复杂性。 不过,Elasticsearch不仅仅是Lucene和全文搜索引擎,它还提供:
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 实时分析的分布式搜索引擎
- 可以扩展到上百台服务器,处理PB级结构化或非结构化数据
而且,所有的这些功能被集成到一台服务器,你的应用可以通过简单的RESTful API、各种语言的客户端甚至命令行与之交互。上手Elasticsearch非常简单,它提供了许多合理的缺省值,并对初学者隐藏了复杂的搜索引擎理论。它开箱即用(安装即可使用),只需很少的学习既可在生产环境中使用。Elasticsearch在Apache 2 license下许可使用,可以免费下载、使用和修改。 随着知识的积累,你可以根据不同的问题领域定制Elasticsearch的高级特性,这一切都是可配置的,并且配置非常灵活。
2. ES中的重要概念
Elasticsearch有几个核心概念。从一开始理解这些概念会对整个学习过程有莫大的帮助。
(1)接近实时(NRT)
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒)。
(2)集群(cluster)
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。在产品环境中显式地设定这个名字是一个好习惯,但是使用默认值来进行测试/开发也是不错的。
(3)节点(node)
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
(4)索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。索引类似于关系型数据库中Database的概念。在一个集群中,如果你想,可以定义任意多的索引。
(5)类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。类型类似于关系型数据库中Table的概念。
(6)文档(document)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。文档类似于关系型数据库中Record的概念。实际上一个文档除了用户定义的数据外,还包括_index、_type和_id字段。
(7)分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。复制之所以重要,主要有两方面的原因: - 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的。
以上部分内容转自Elasticsearch基础教程
3. ES的安装
ES具有开箱即用的特点,只需要在官网下载压缩包,解压就可以直接使用。这里演示的是windoxs版本的安装与配置,打开官网下载页面,选择相应版本点击下载即可。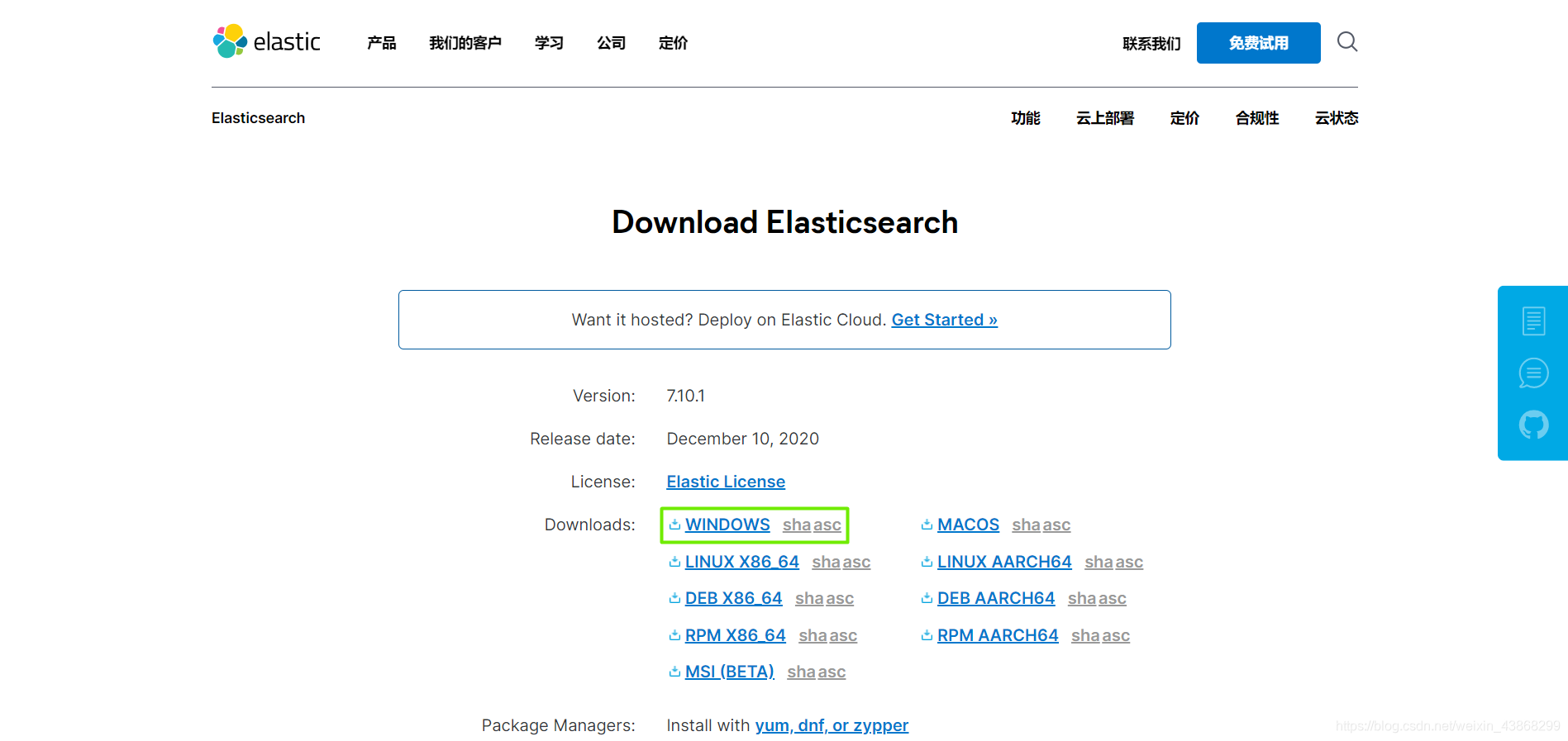
如果想下载历史版本,可以下滑点击past releases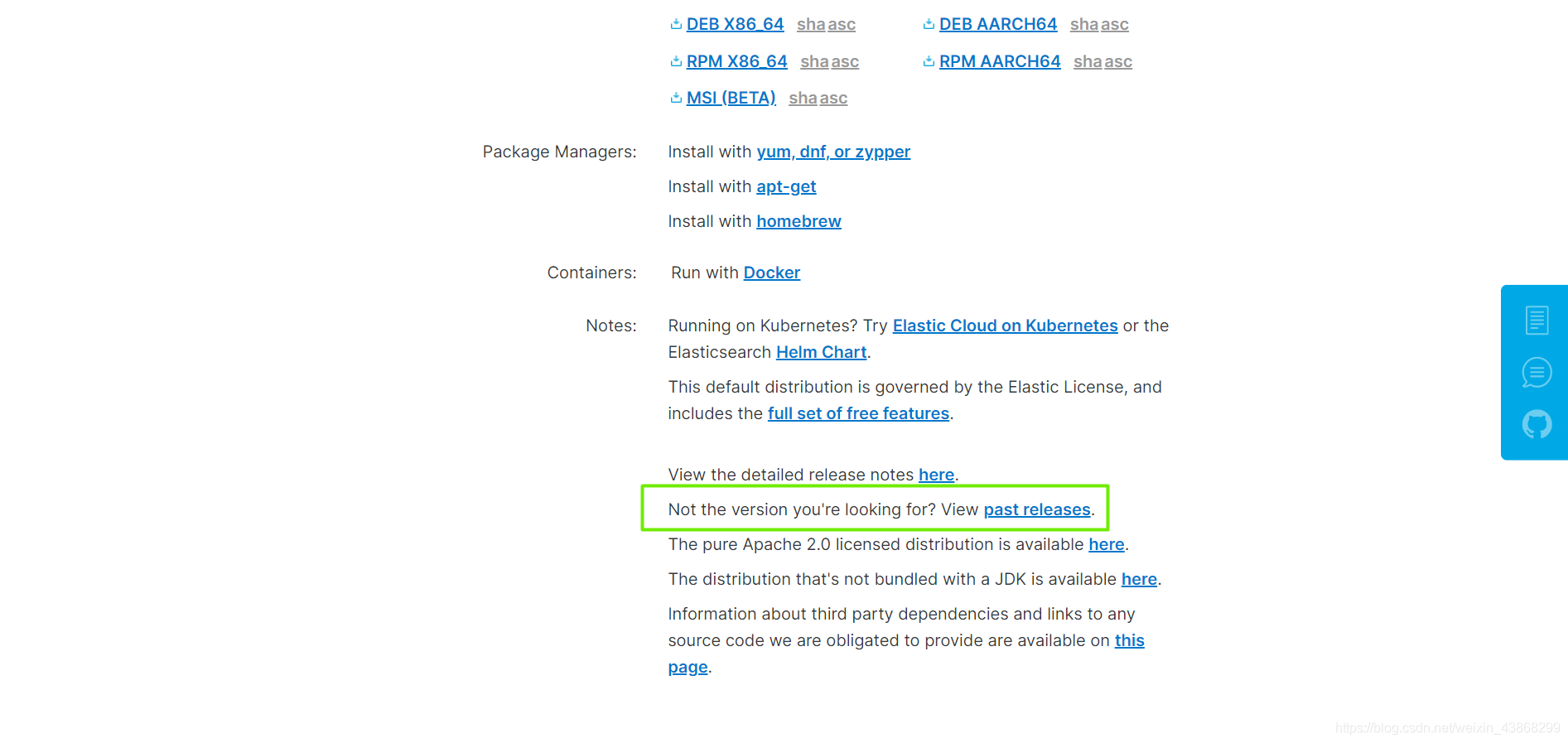
下载解压后打开ES的bin目录,点击elasticsearch.bat启动ES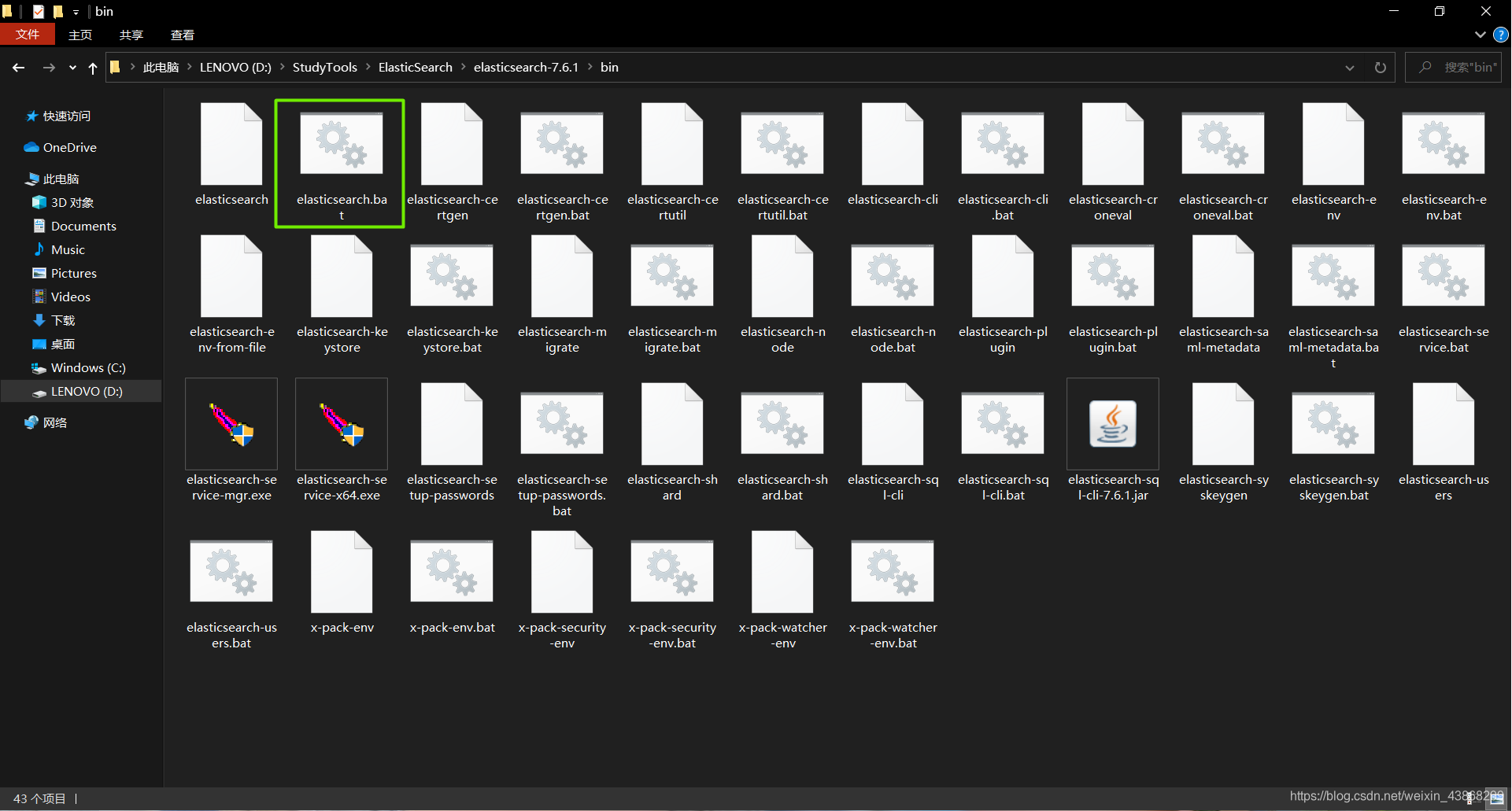
启动成功后,打开浏览器输入localhost:9200。如果显示下面的信息,则表示ES安装成功。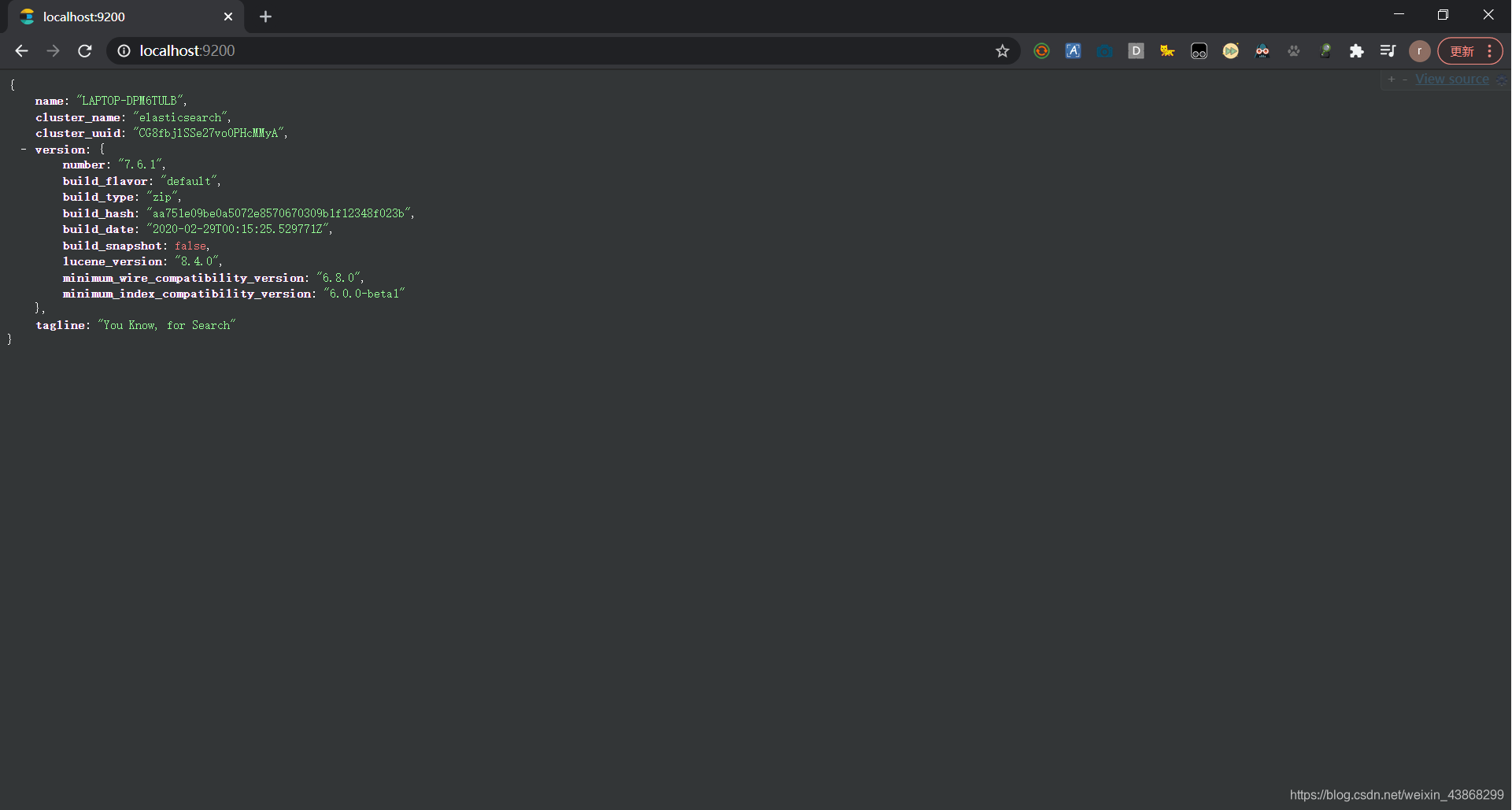
4. ES可视化工具 – ElasticSearch-head
ElasticSearch-head可以对ES数据进行可视化操作,可以通过下载ElasticSearch-head插件,放入ES下的plugins插件目录。最快捷的方式是直接下载chrome插件,在浏览器安装插件即可。
ElasticSearch-head的安装可以参考可视化工具之elasticsearch-head
5. Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。
Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态。
设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
5.1 Kibana安装
Kibana也是开箱即用,只需下载解压安装包即可使用。下载时要选择与ES对应的版本!解压完成后进入bin目录下点击kibana.bat启动
下载地址: https://www.elastic.co/downloads/kibana
5.2 Kibana使用
打开浏览器输入http://localhost:5601/
6. 命令模式的使用
6.1 Rest风格说明
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有的数据 |
6.2 命令测试
6.3 创建索引
PUT /索引名{ 请求体 }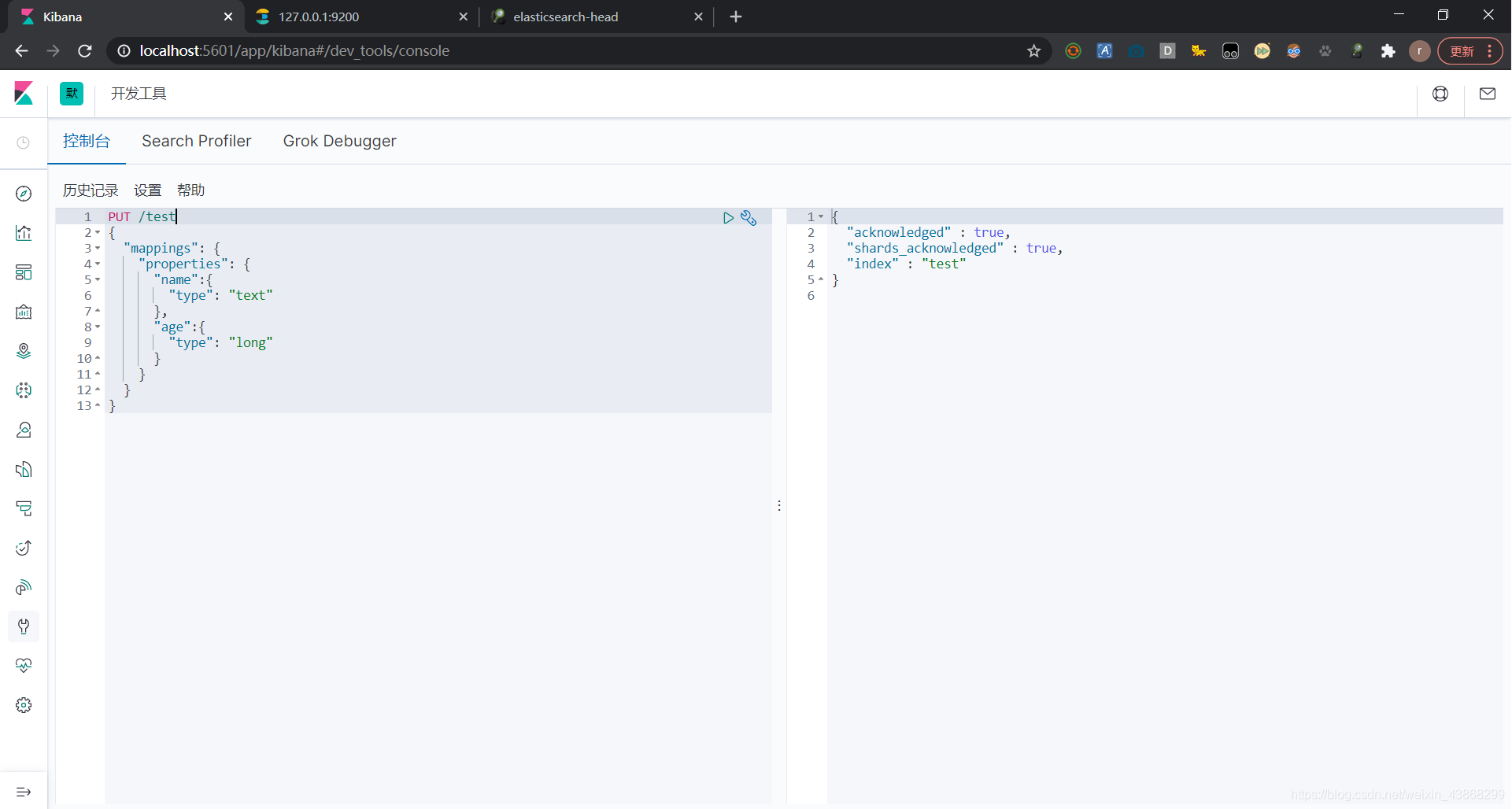
6.2 创建文档
POST /索引名/类型名/文档id{ 请求体 }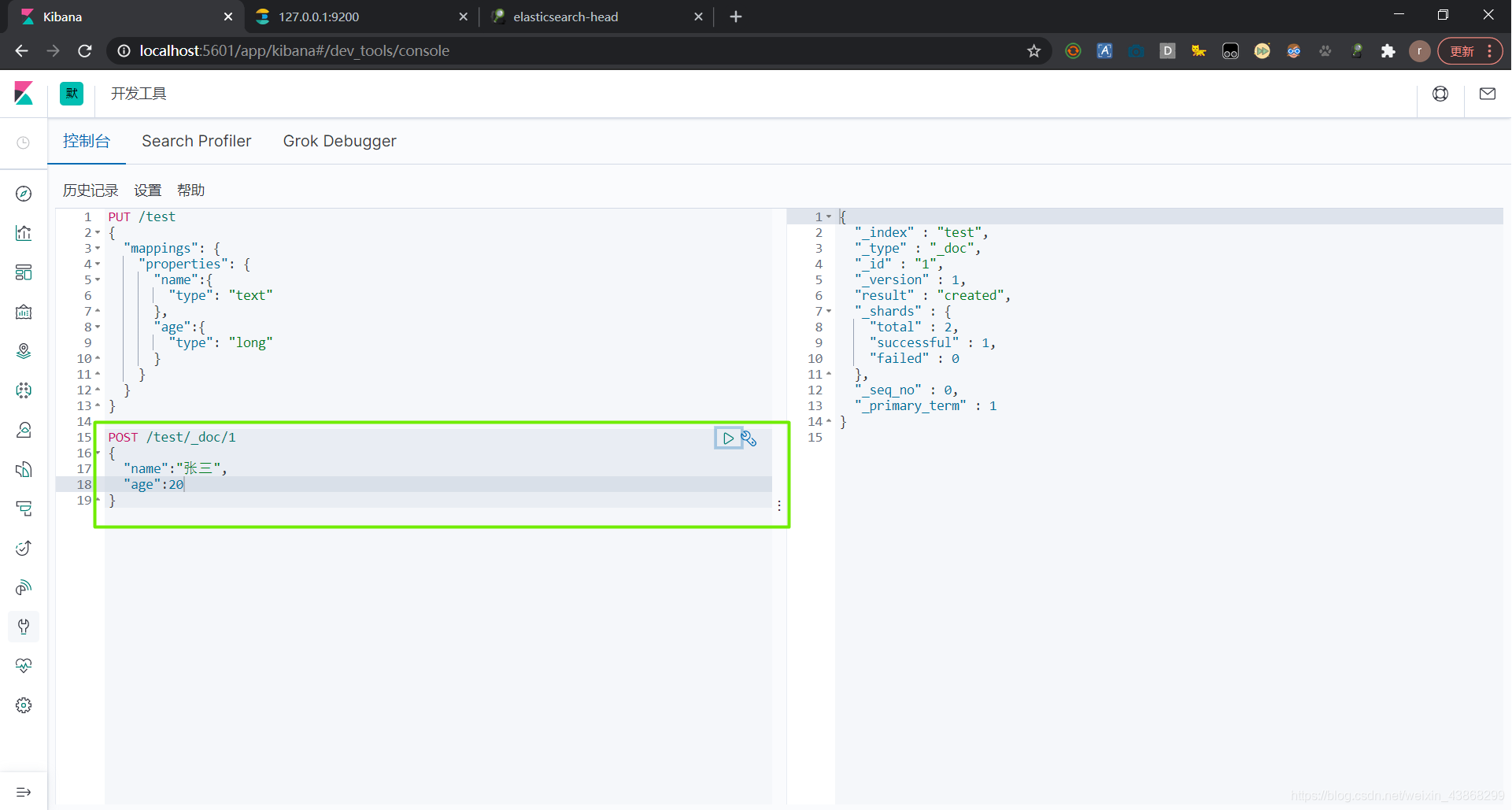
可以先创建索引再创建文档,也可以直接创建文档。这时候ES会创建文档,并自动创建一个索引,将文档放入索引中。文档中的字段类型ES会自动指定默认类型。
POST /test2/_doc/1{ 请求体 }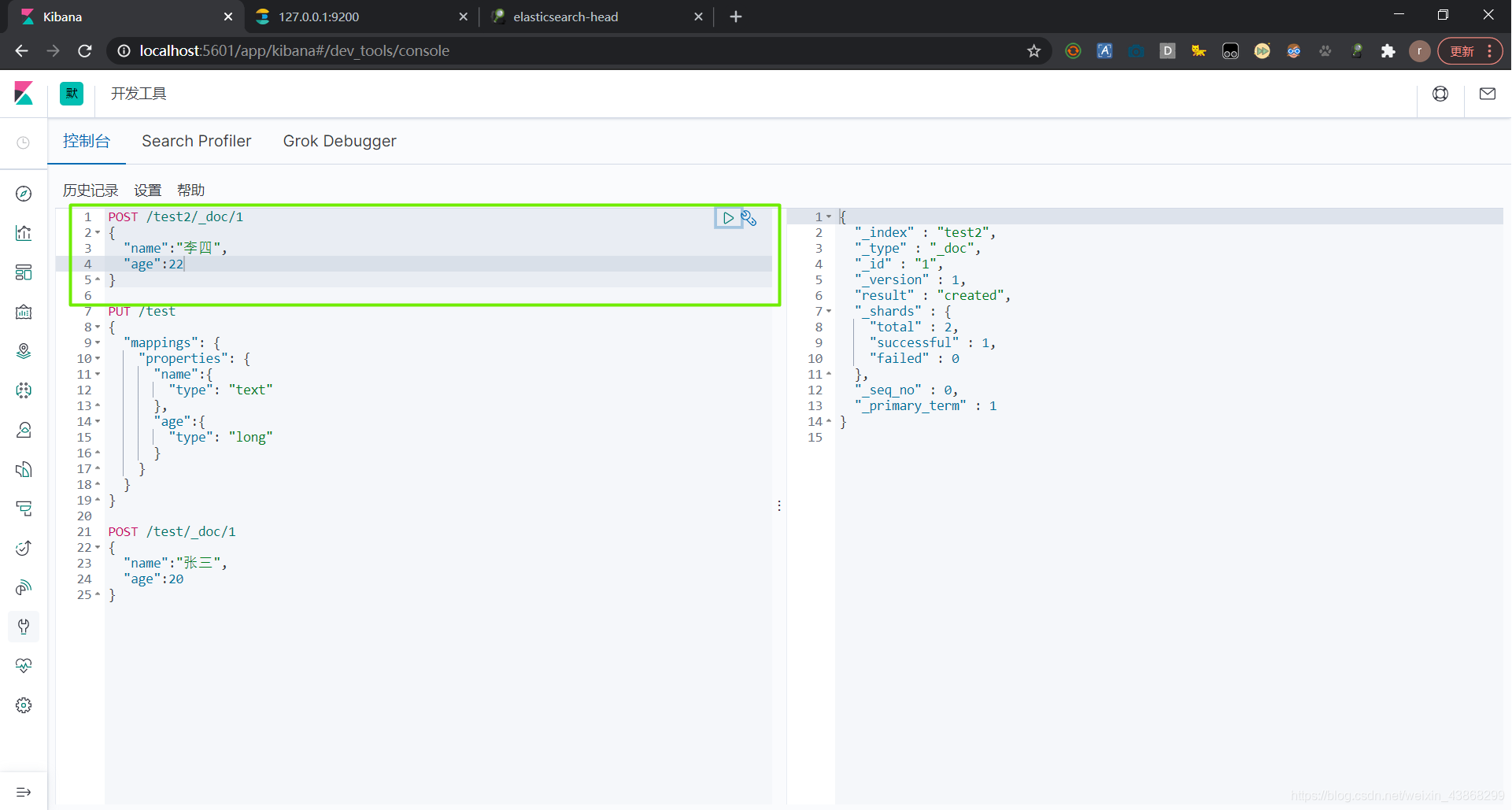
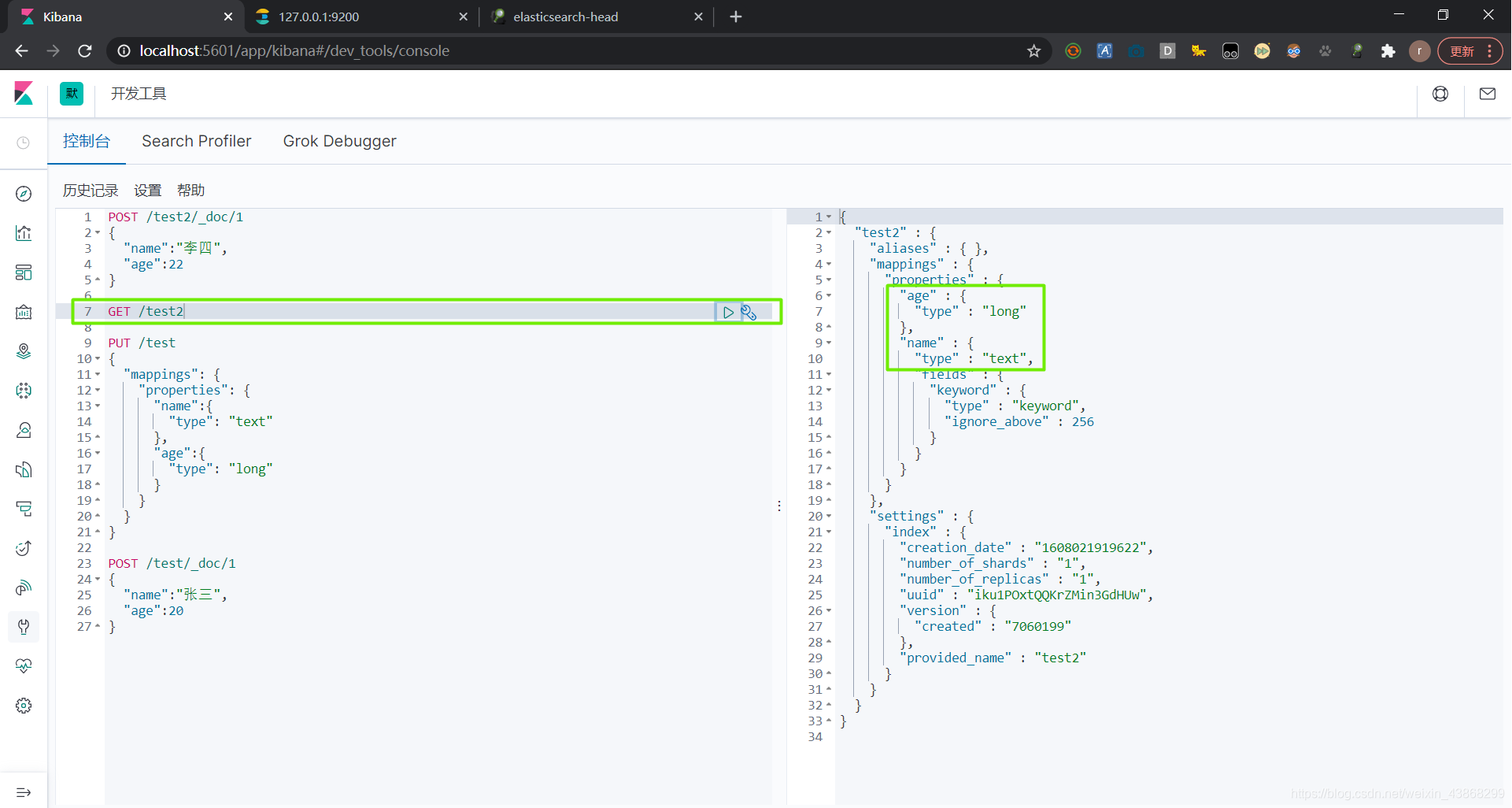
6.3 cat命令
获取健康值 GET _cat/health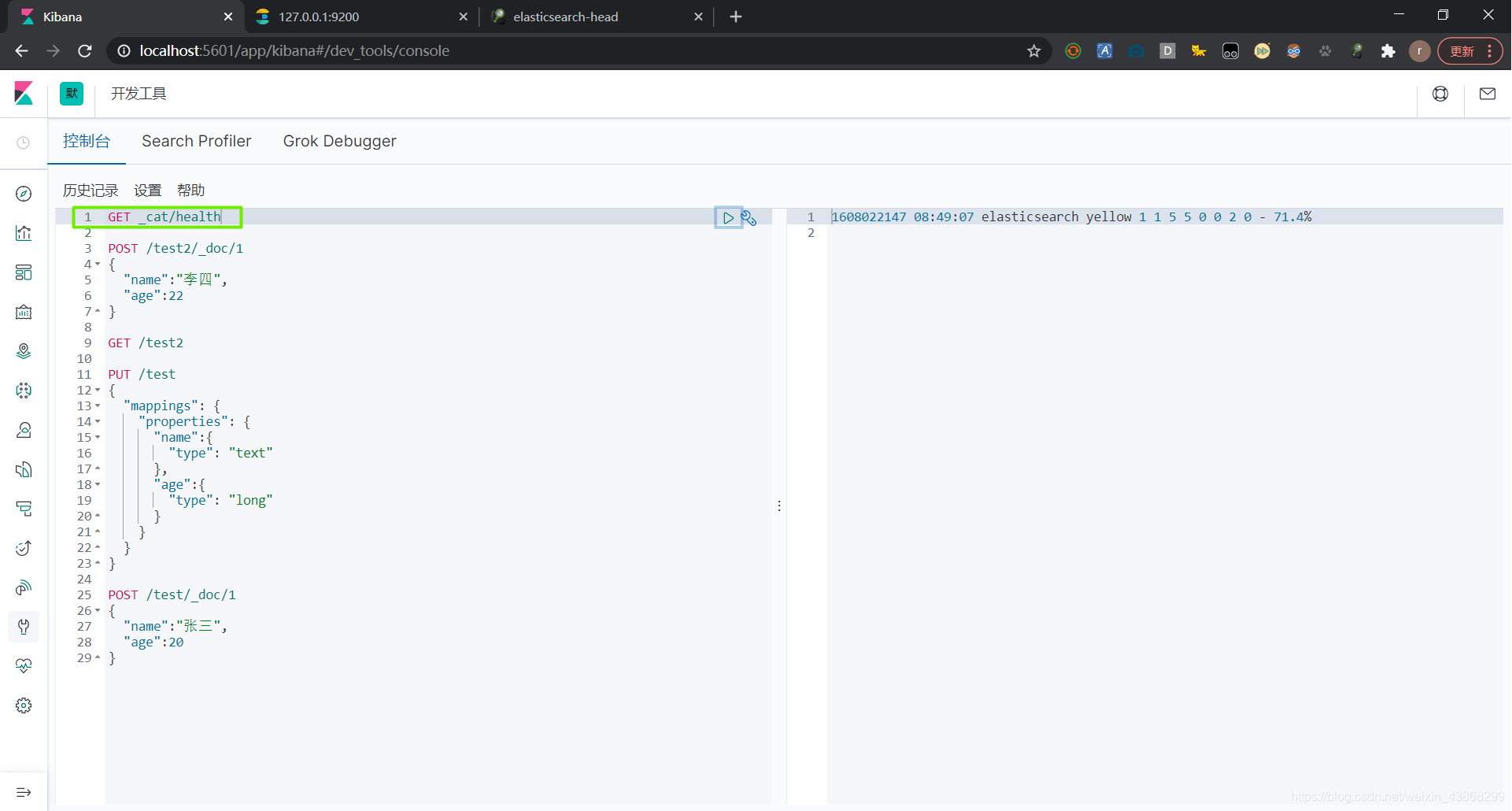
获取所有的信息 GET _cat/indices?v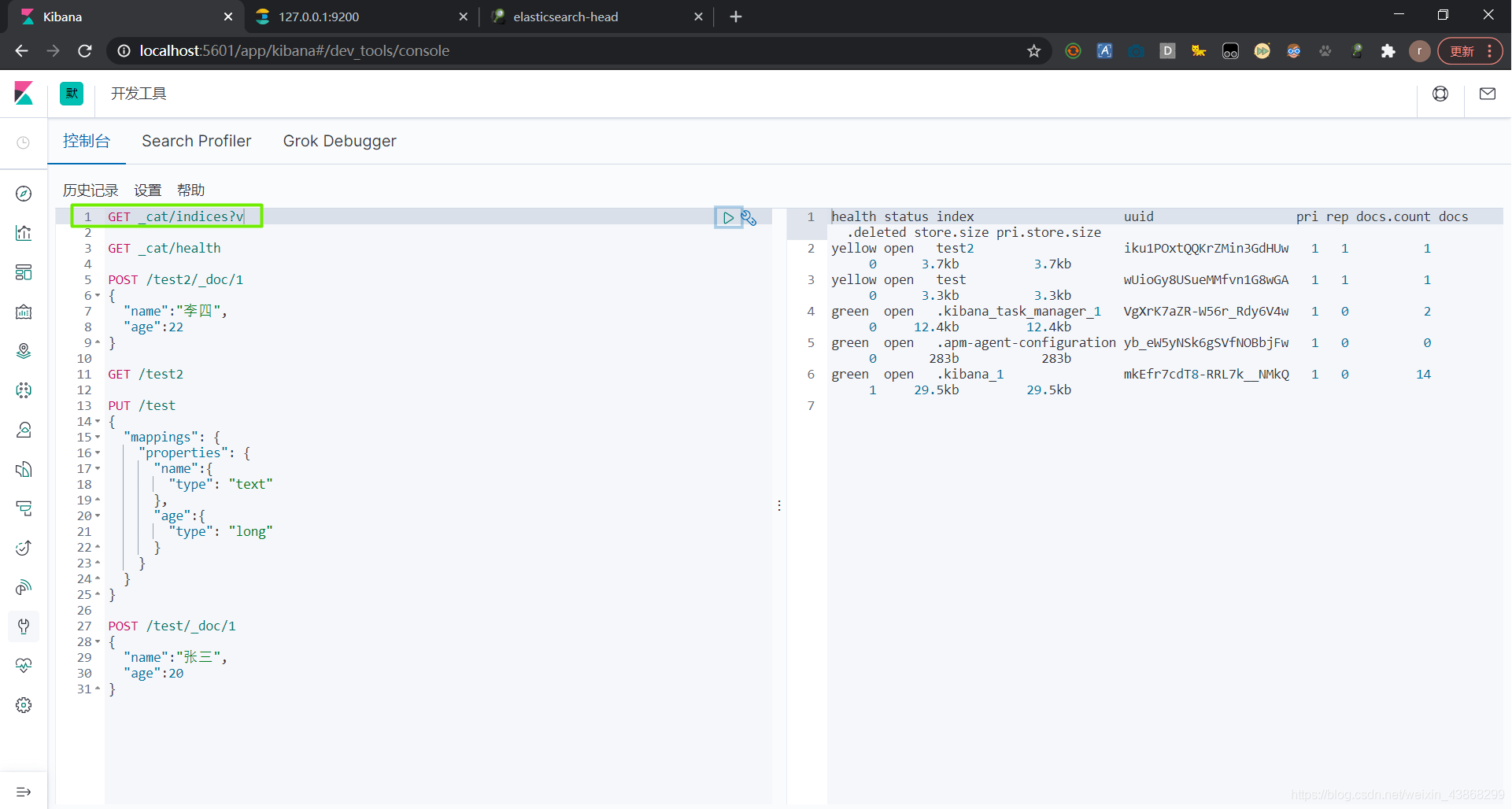
6.4 修改文档
可以使用PUT命令修改,当时PUT修改有个弊端。当使用PUT修改文档的时候,如果文档有某些字段没有修改,则原先的字段会被置空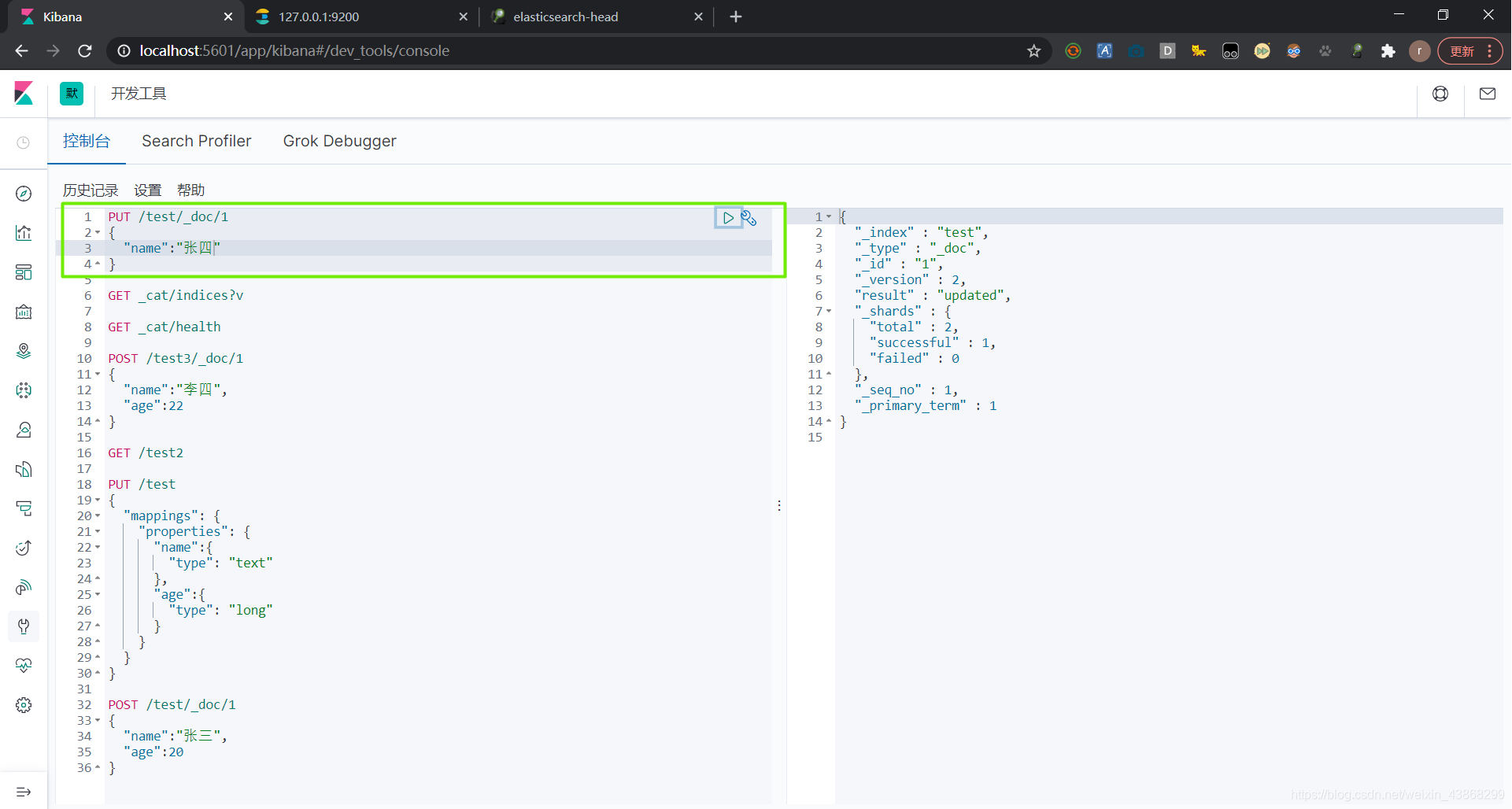
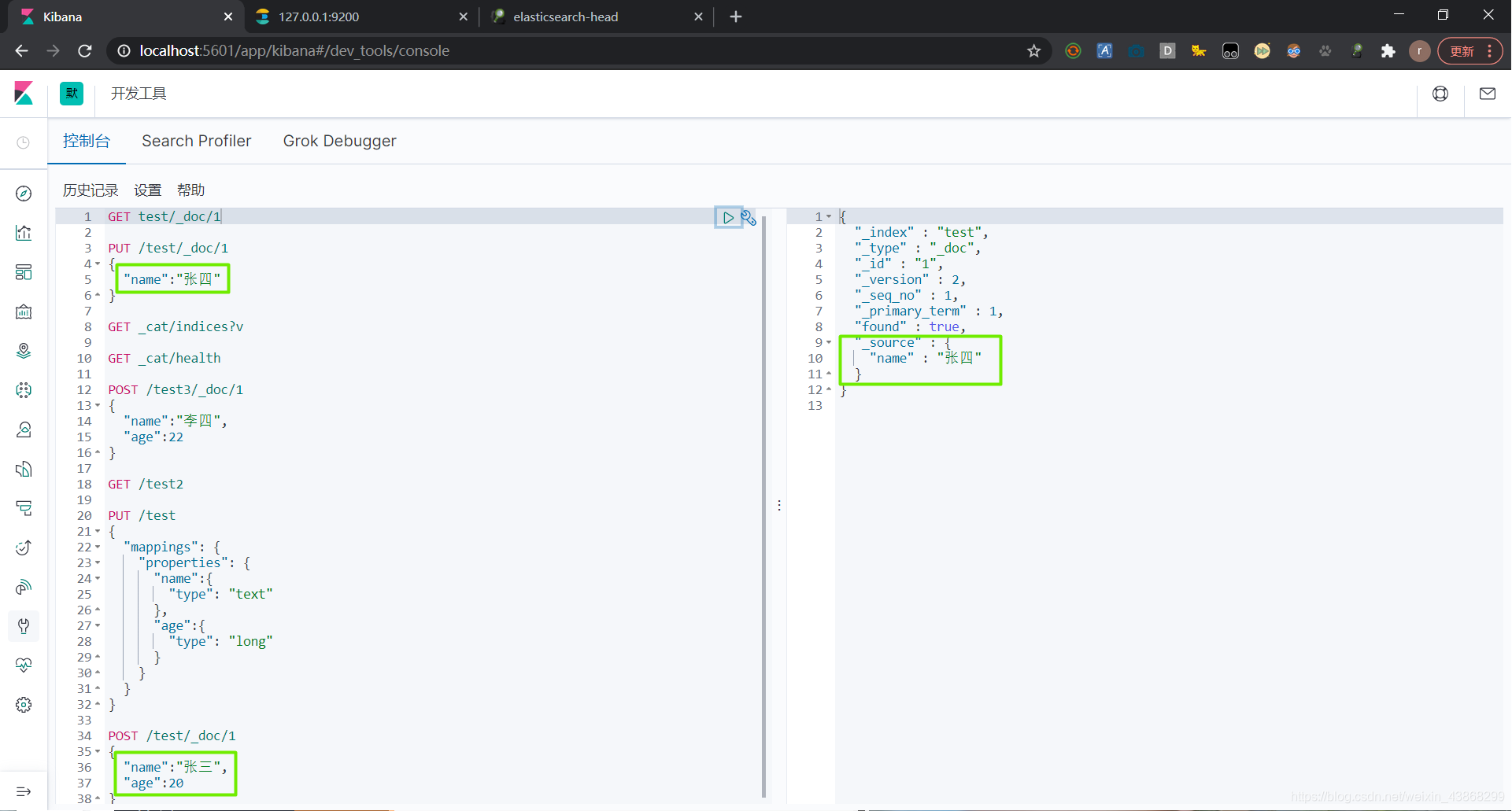
也可以使用POST修改文档,如果不修改某字段,该字段会保留原数据,不会被置空。但是URL上一定要加上_update,不然也会将原字段置空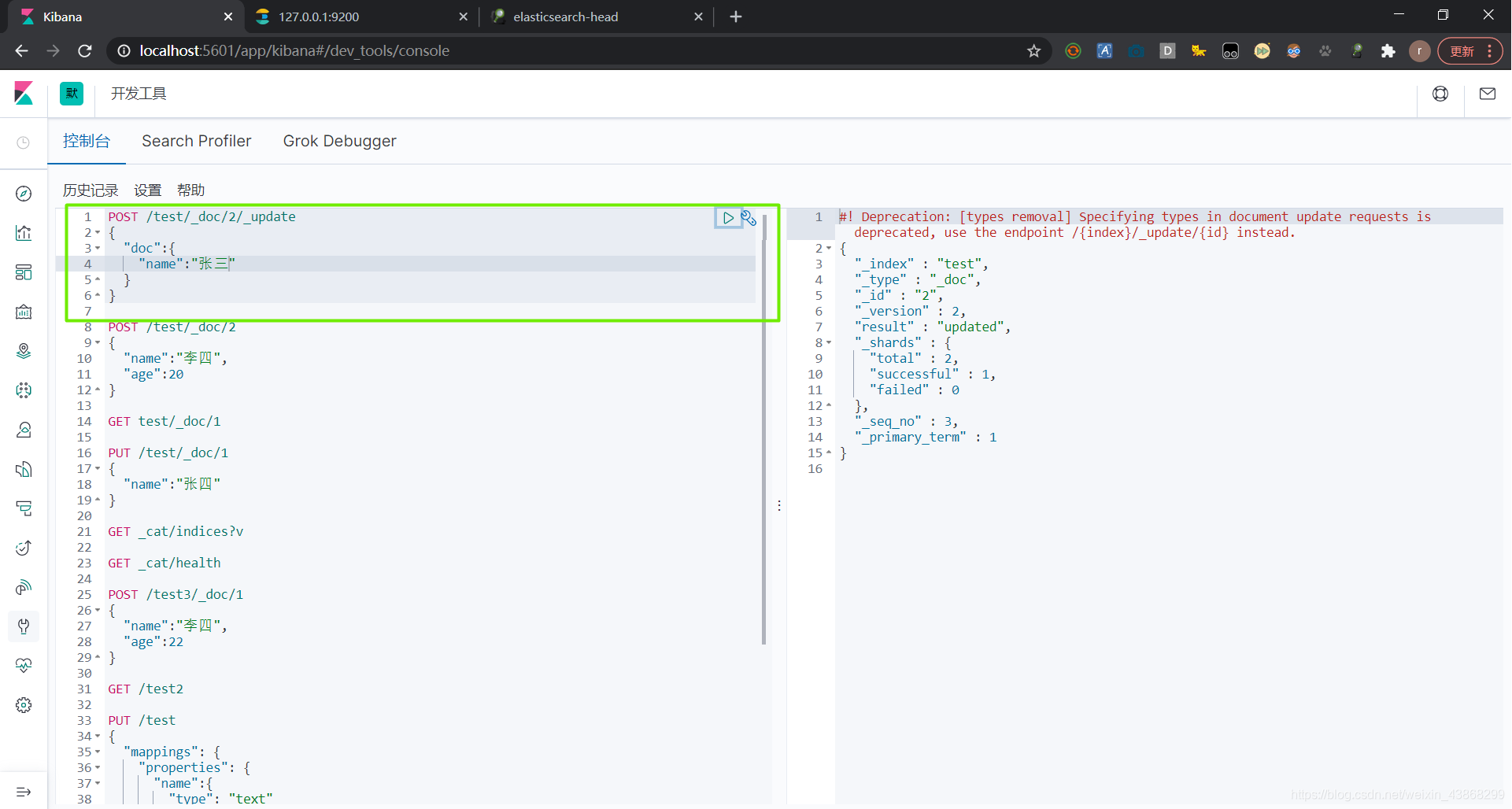
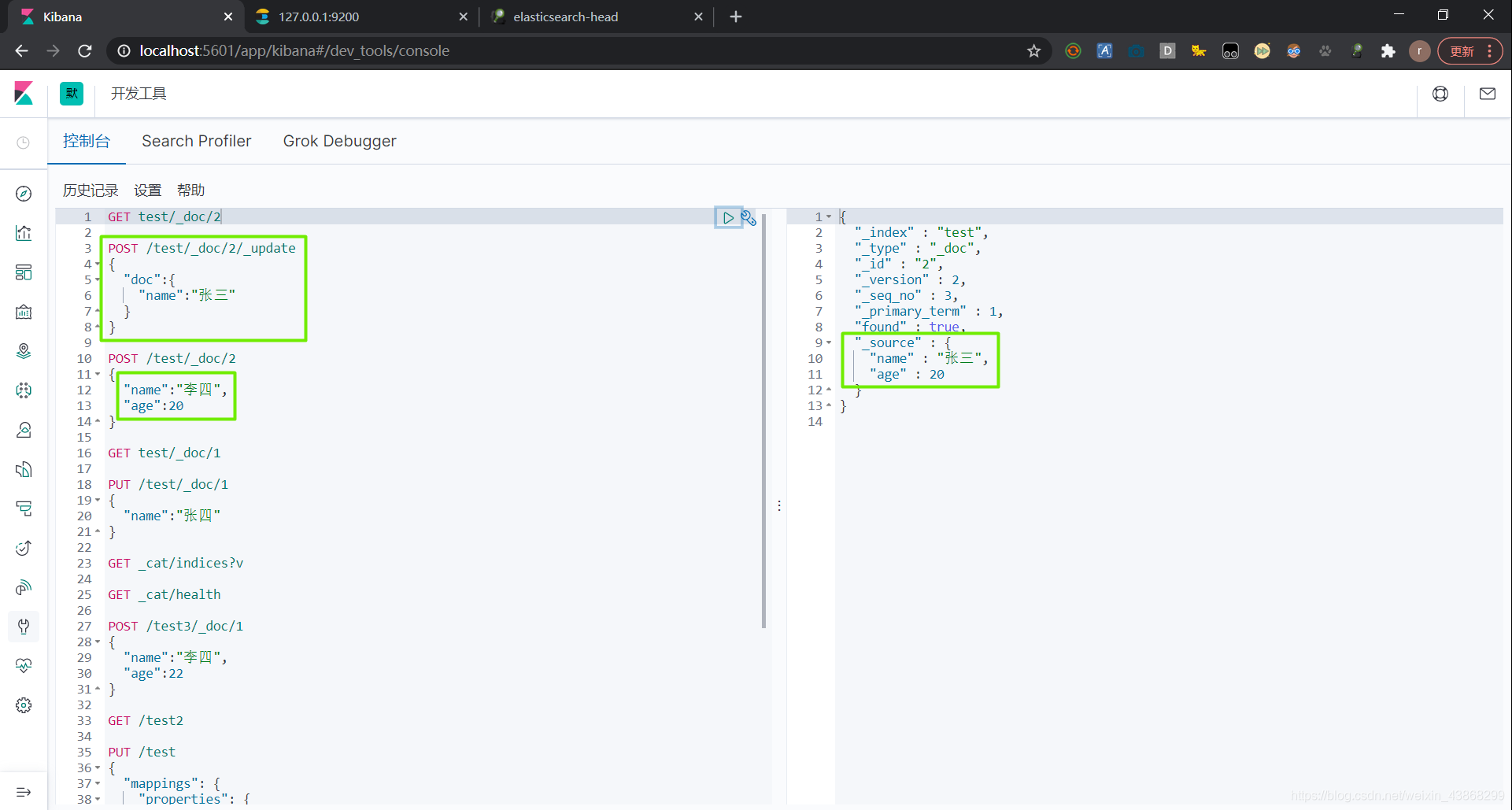
6.5 删除文档
DELETE 索引名/类型名/文档id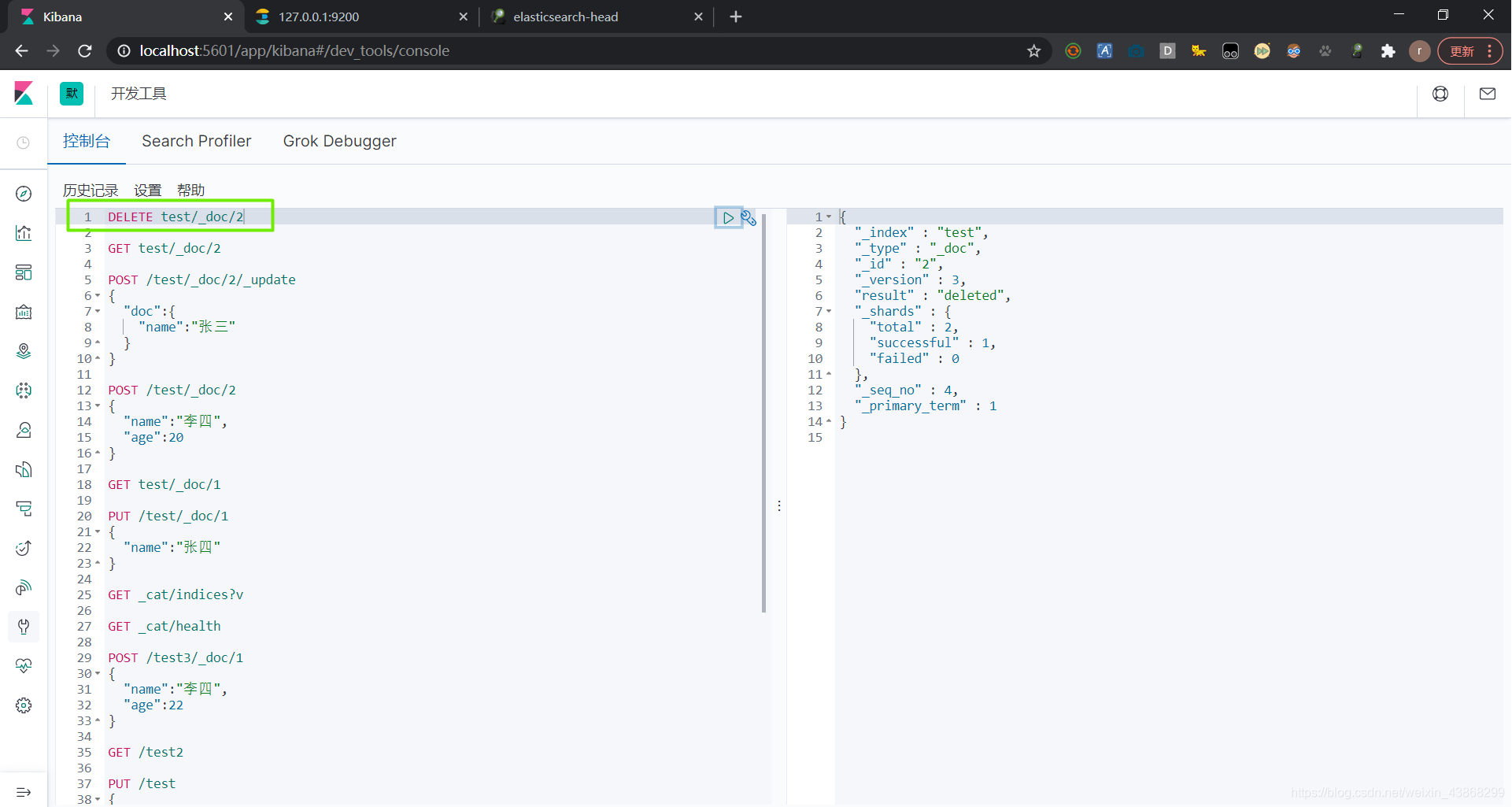
6.6 简单查询
GET 索引名/类型名/_search?q=字段名:字段值
这里搜索的是李四,但是搜索结果是张四。这是因为name字段是text类型,搜索的时候会进行分词搜索。而索引中是没有李四这个文档的,所以搜索结果只有一个张四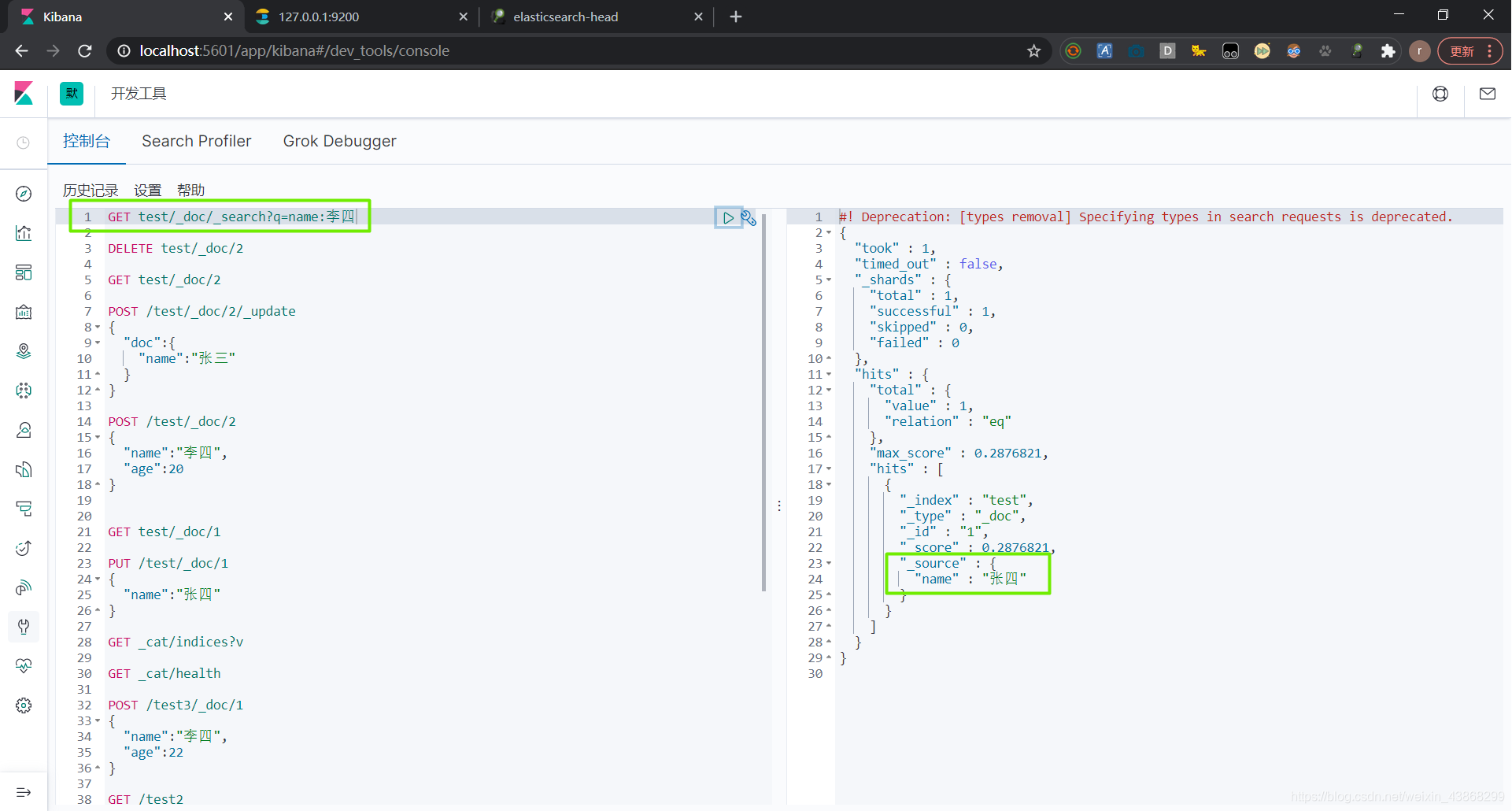
6.7 复杂搜索
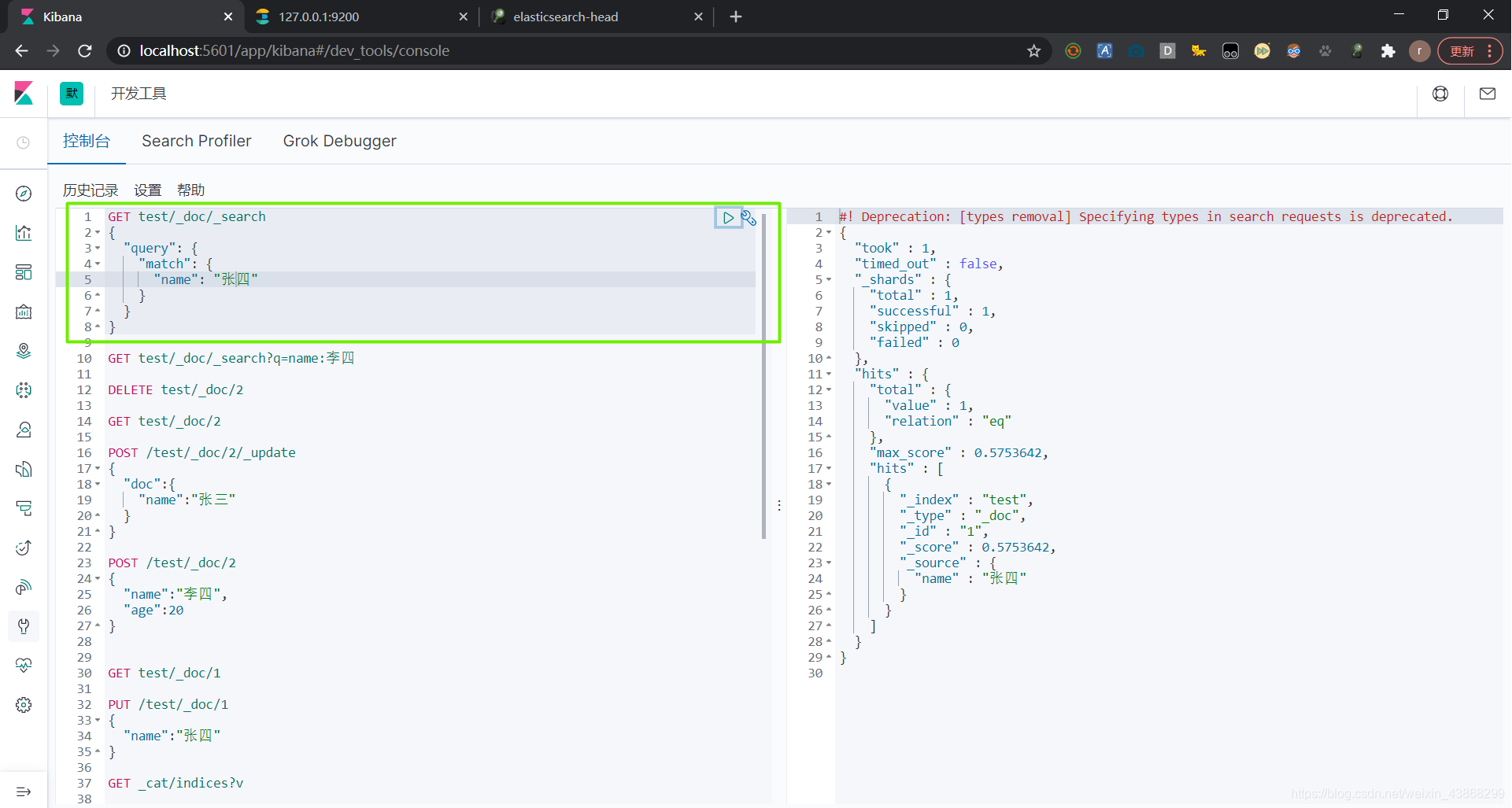
(1)结果过滤,只展示列表中某些字段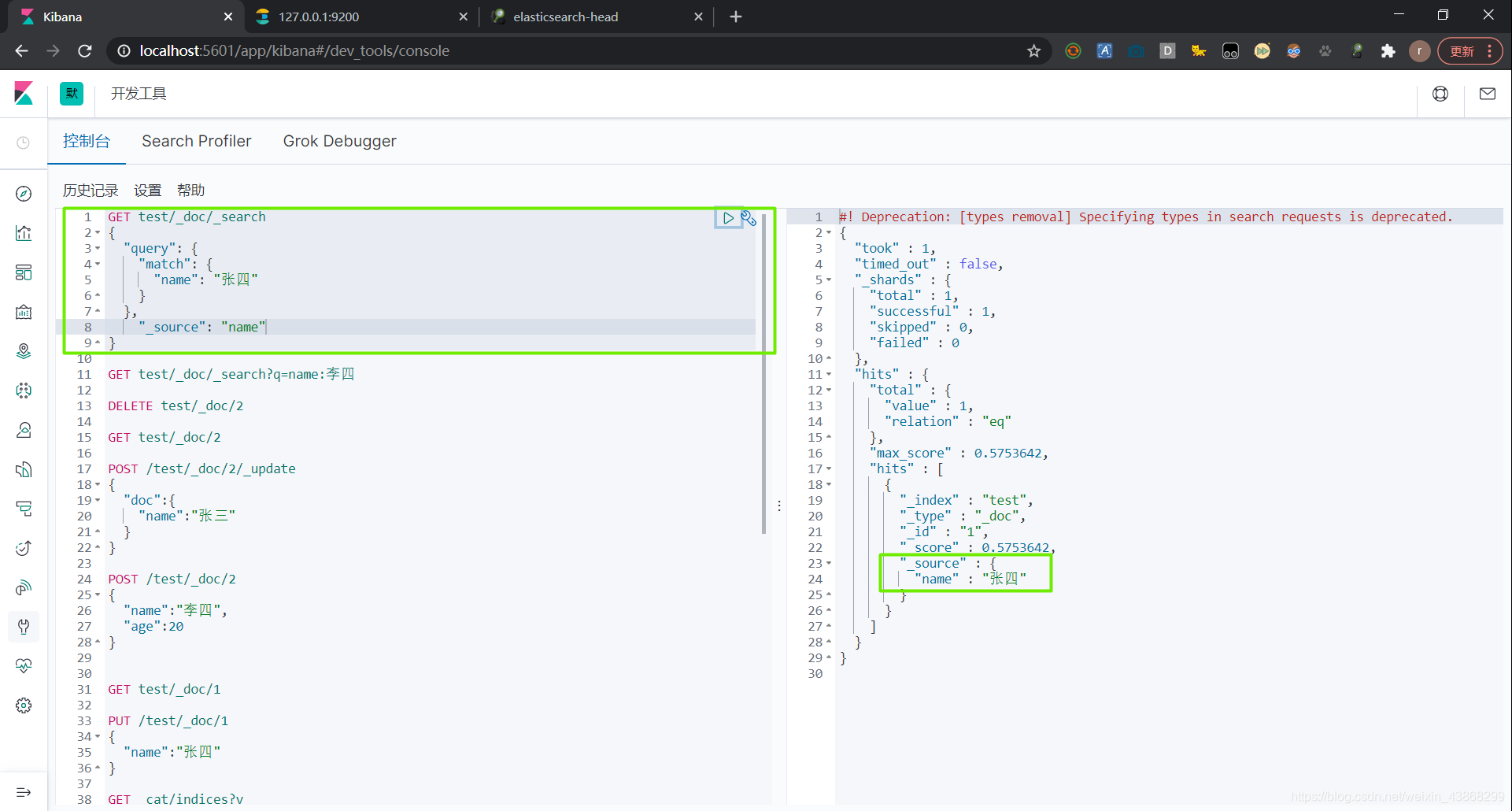
(2)包含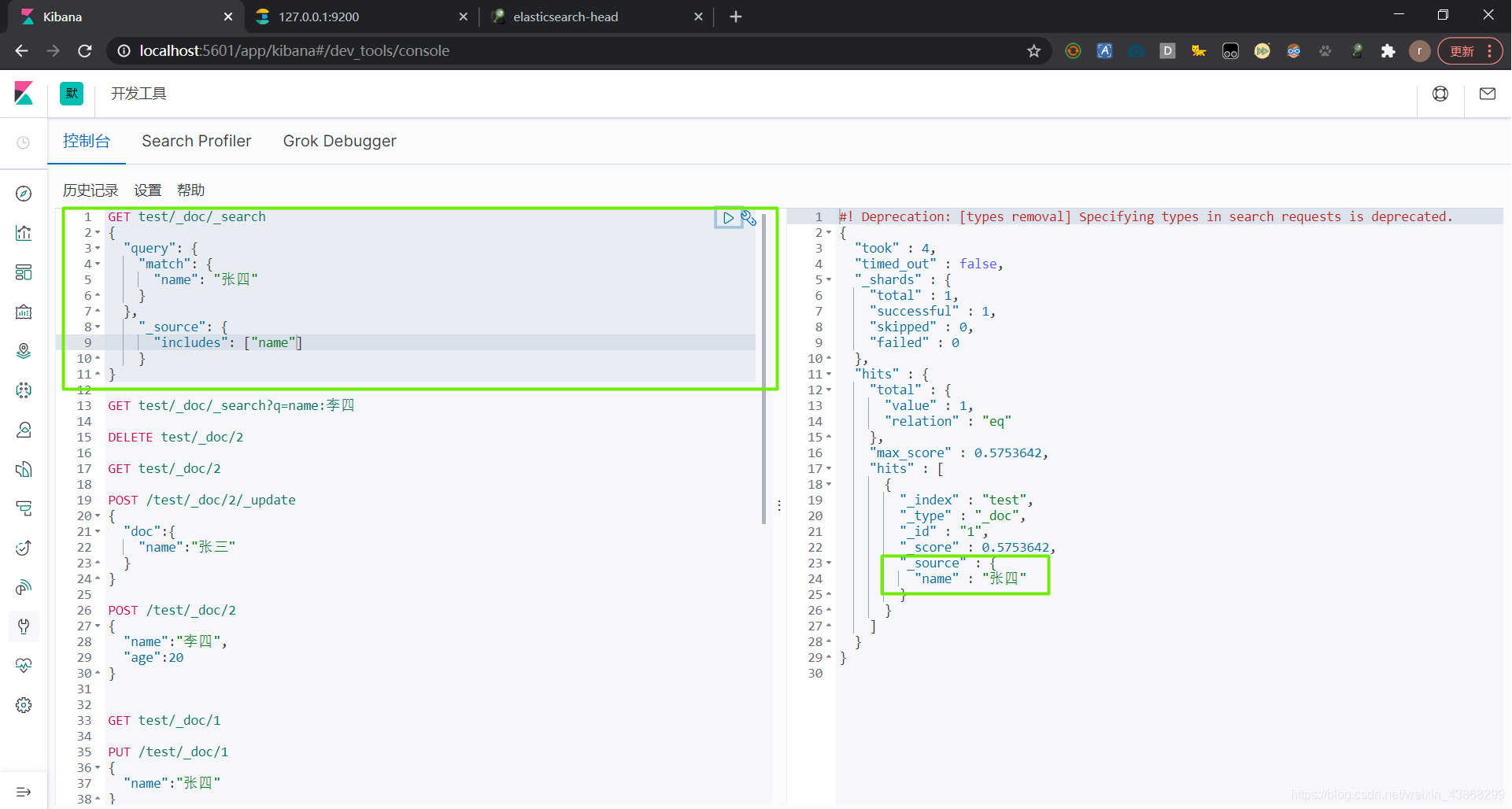
(3)不包括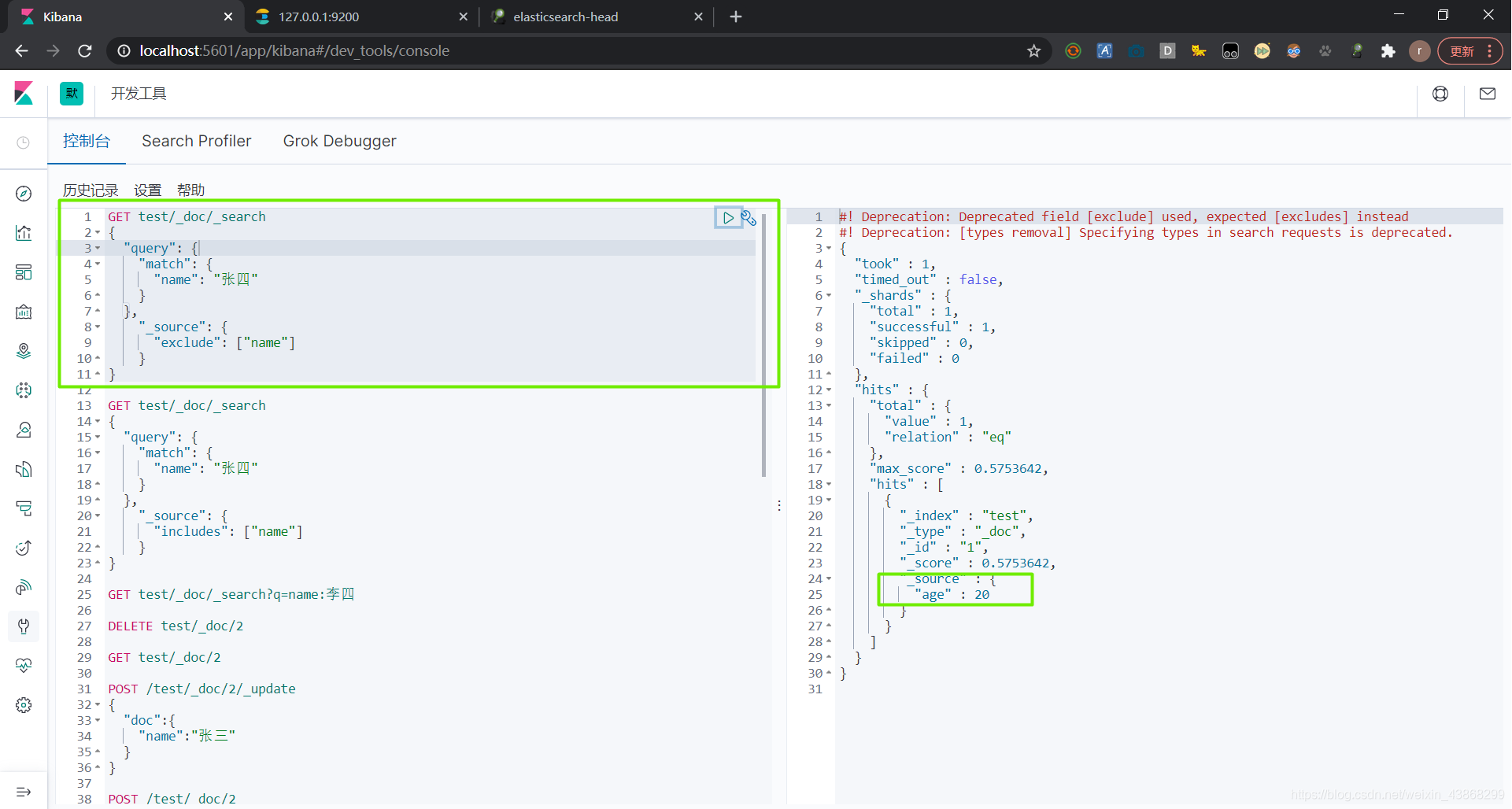
(4)排序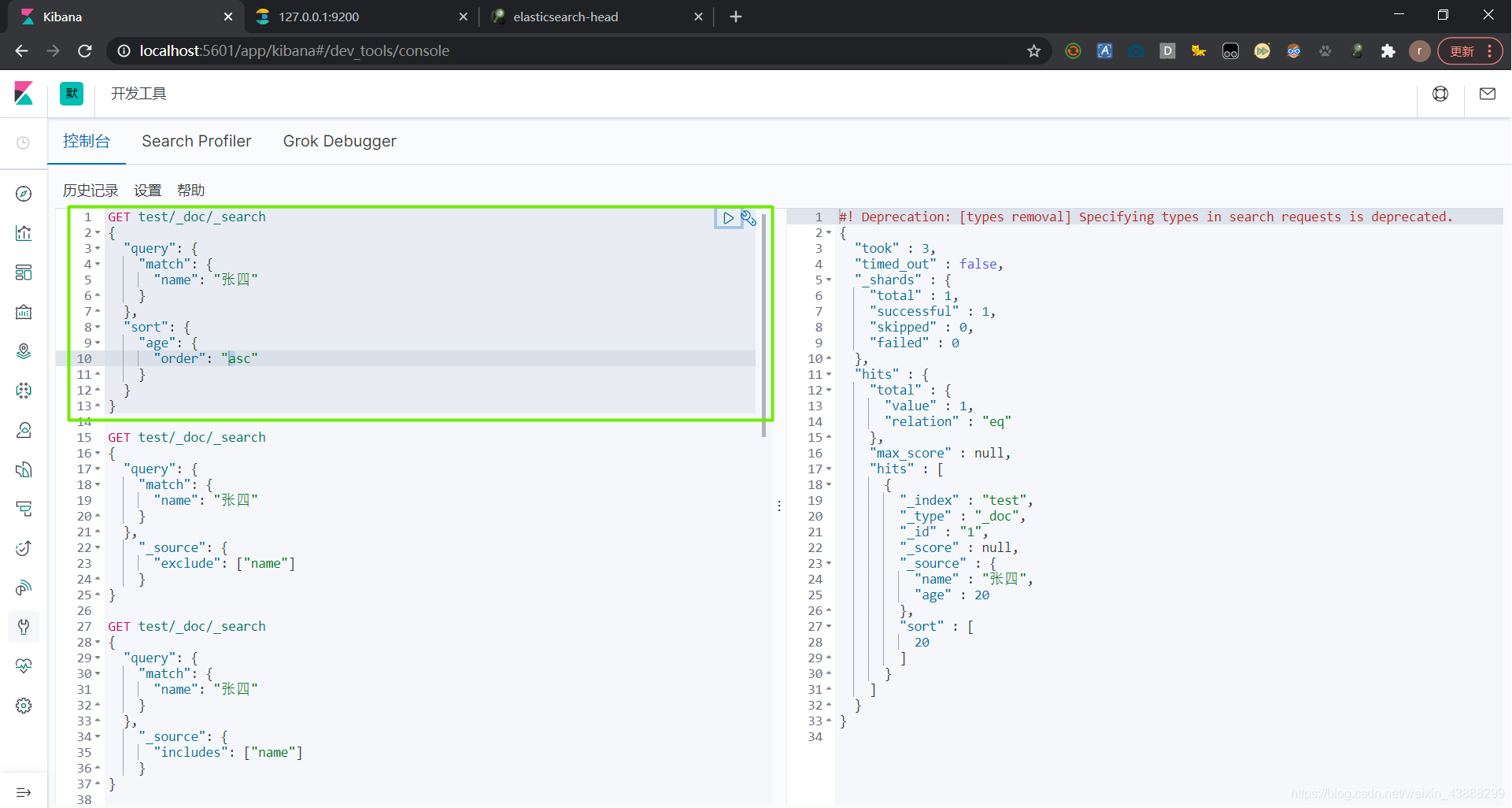
(5)分页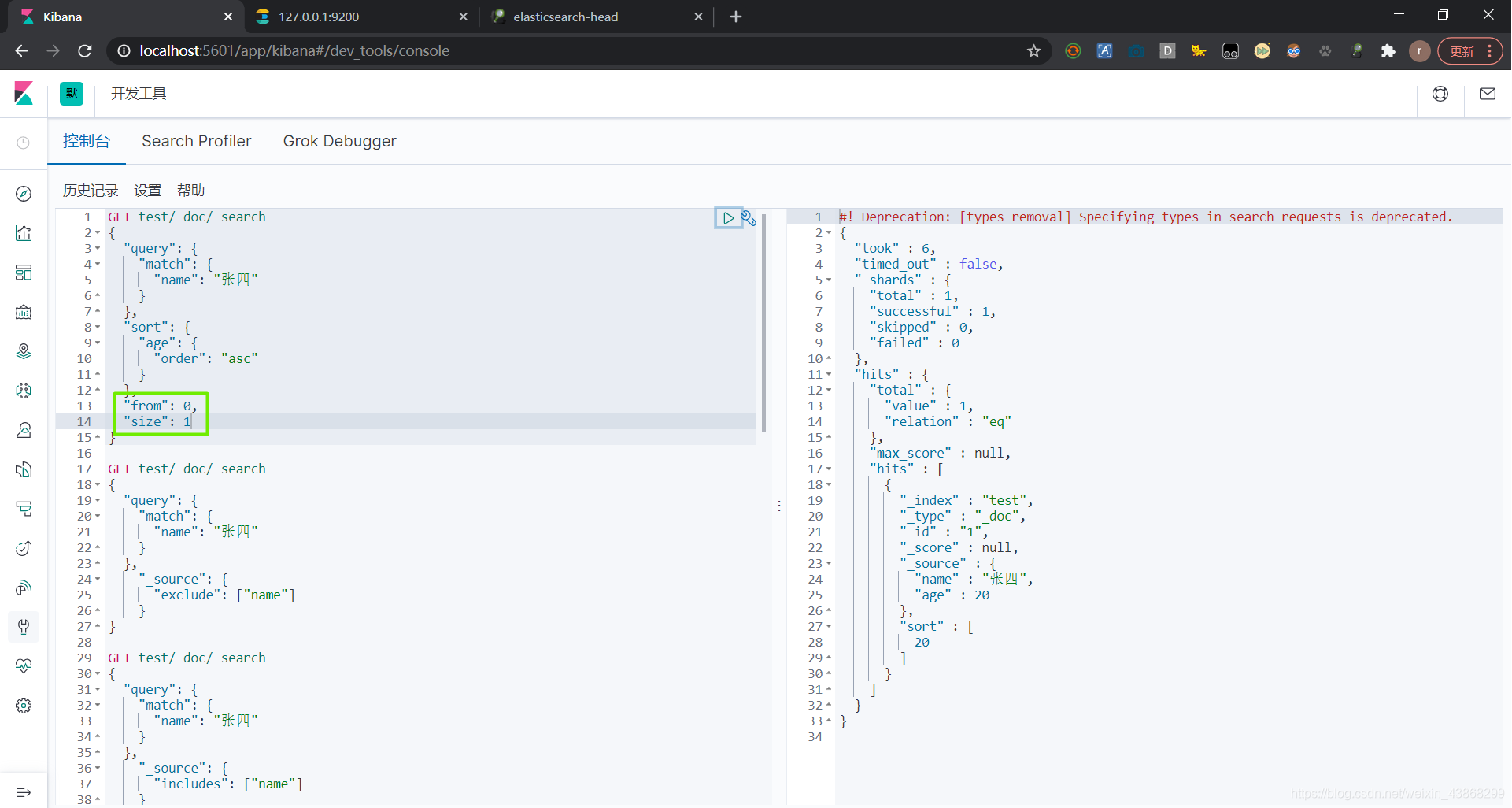
6.8 多条件查询
(1)布尔值查询——must 必须所有条件符合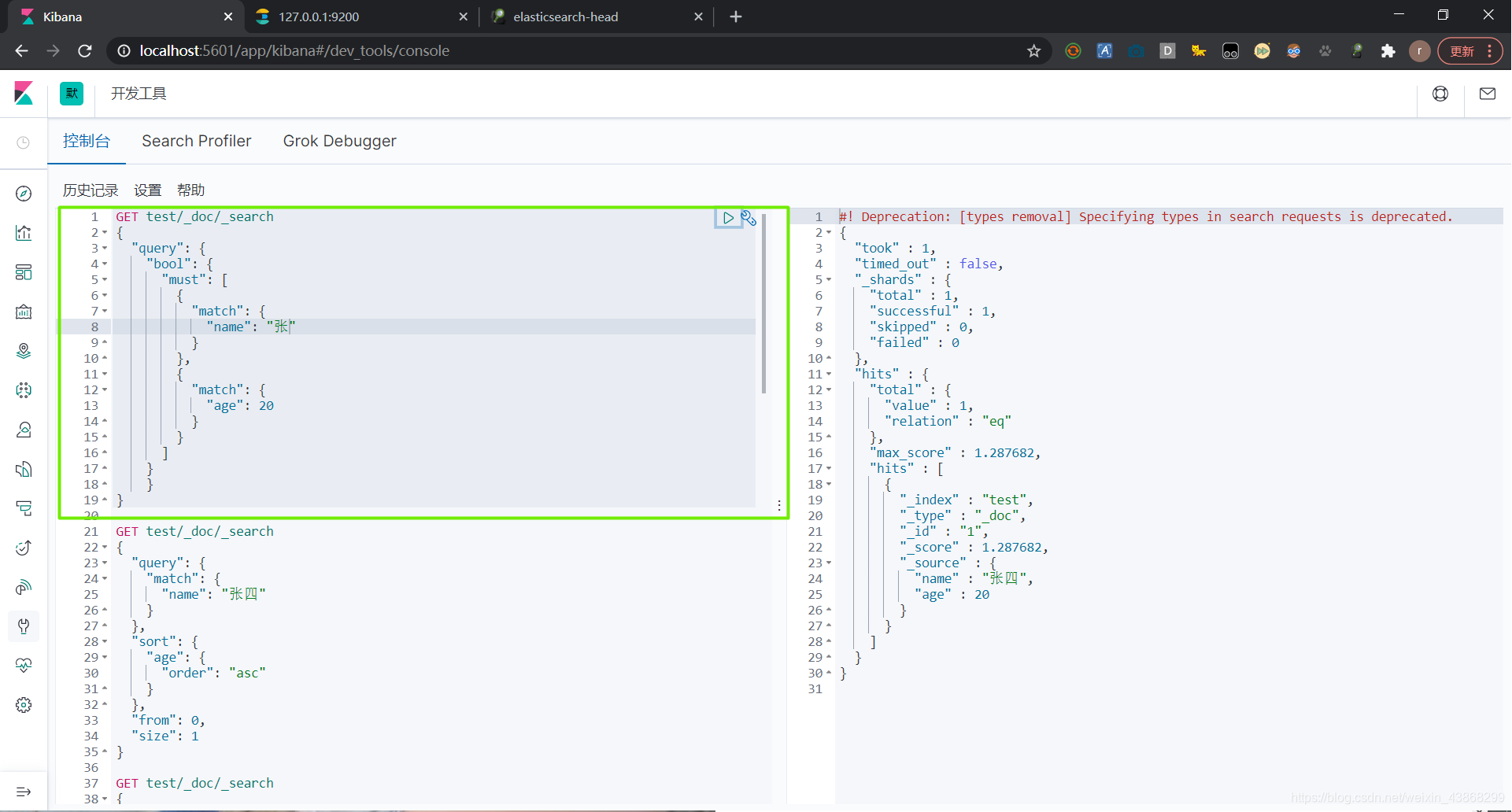
(2)布尔值查询——should 符合某一条件即可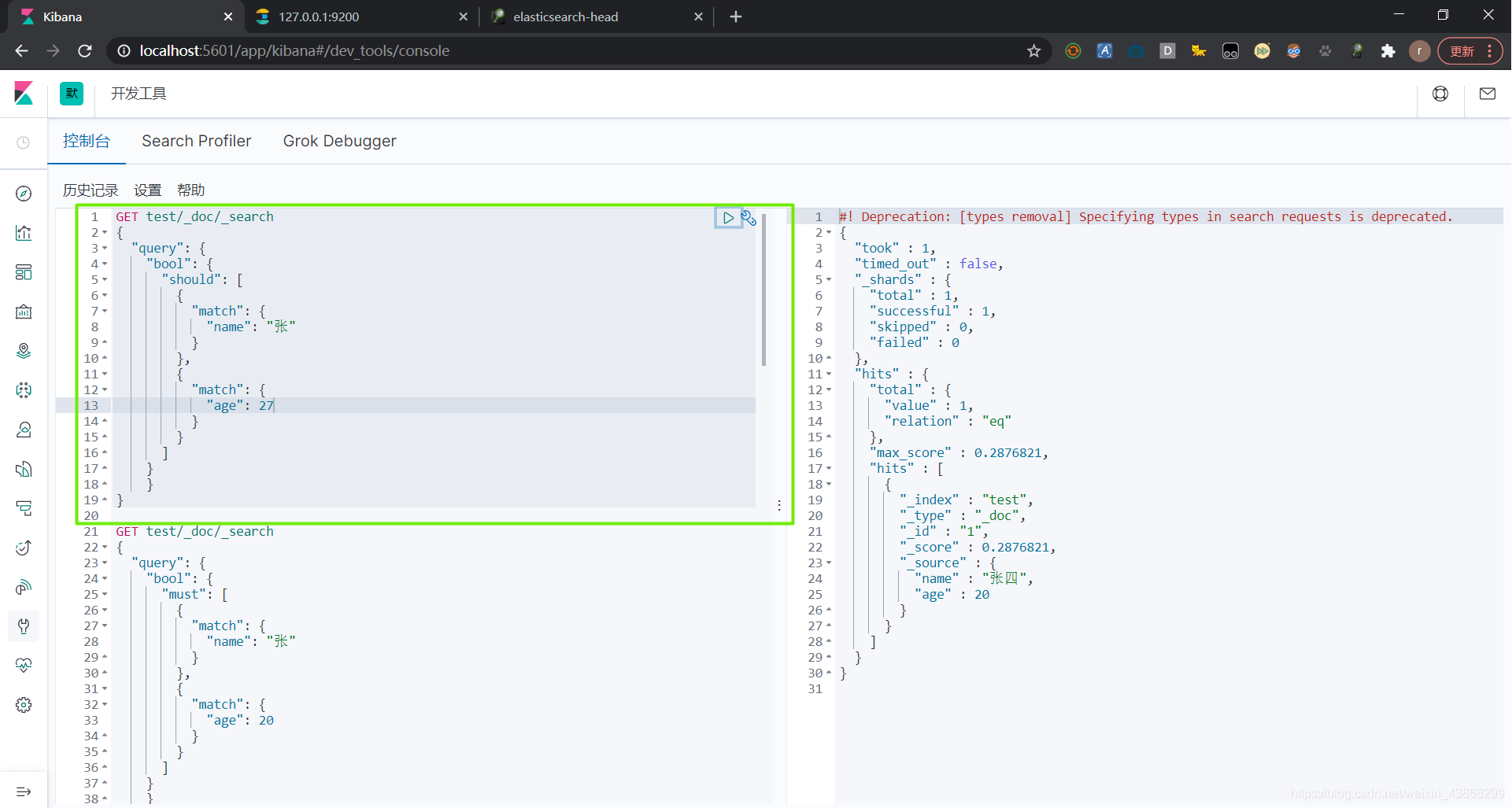
(3)布尔值查询——must_not 不符合条件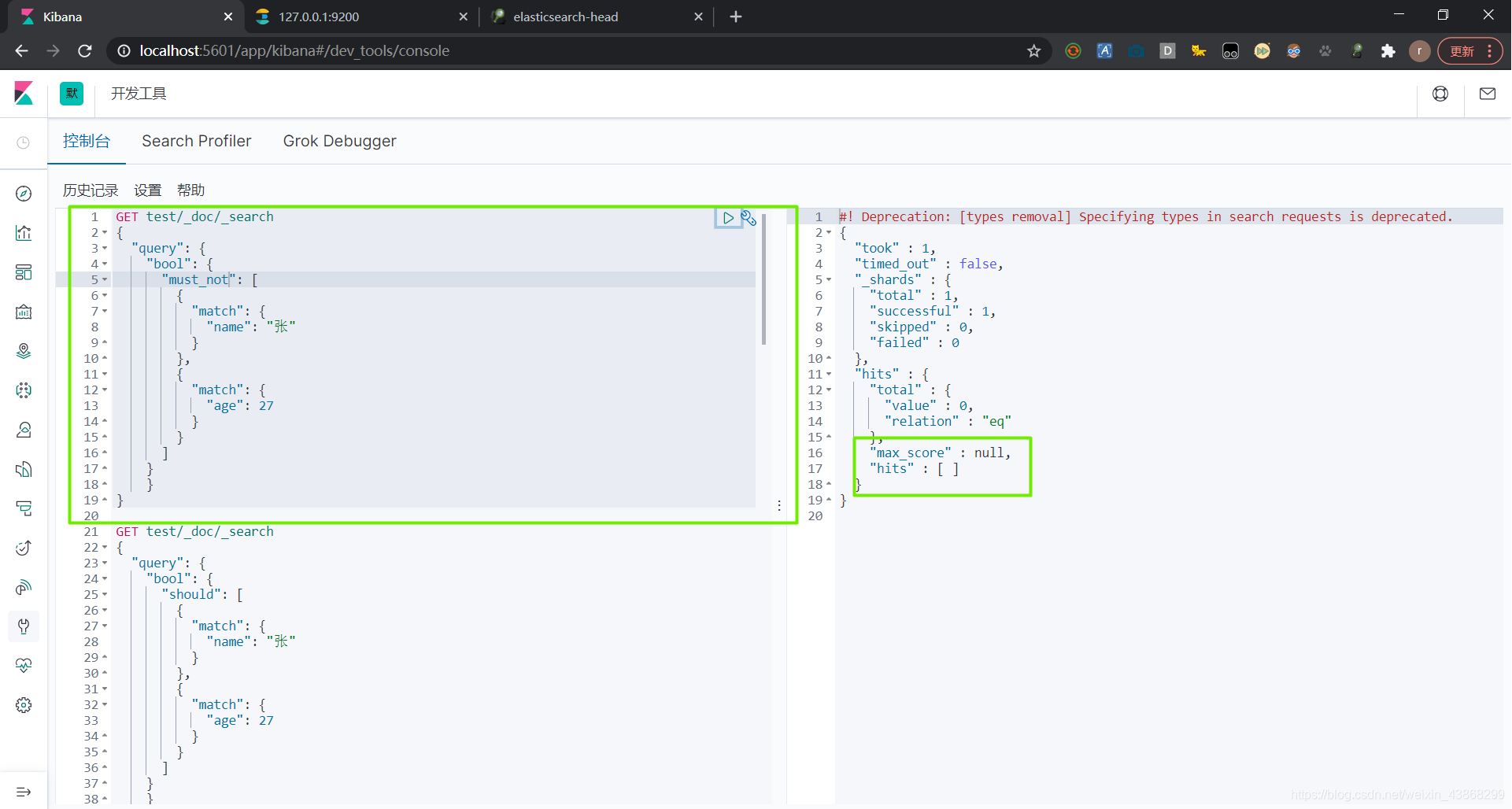
(4)布尔值查询——条件区间
- gt大于
- gte大于等于
- lte小于
- lte小于等于
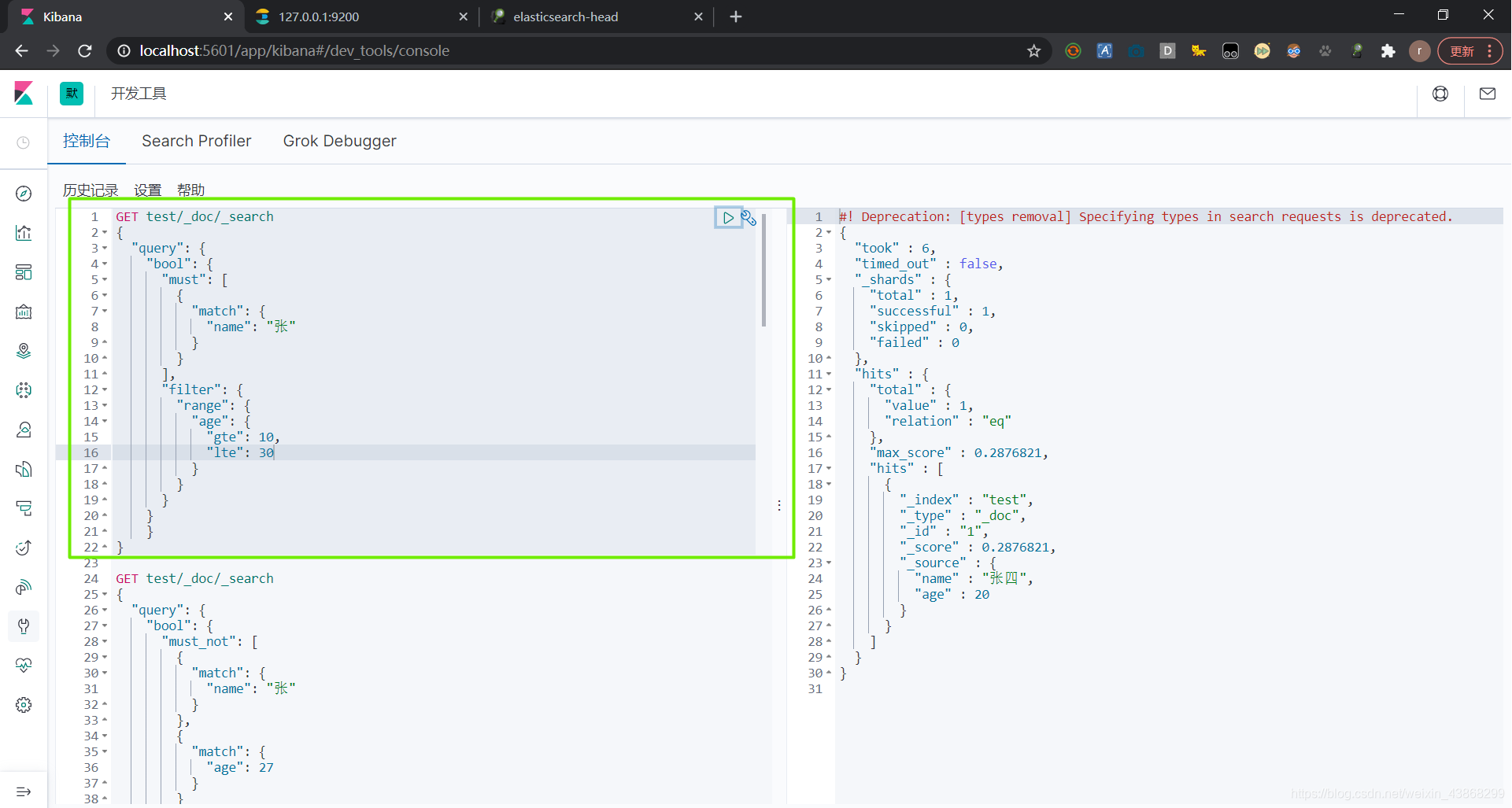
6.9 高亮+自定义高亮样式
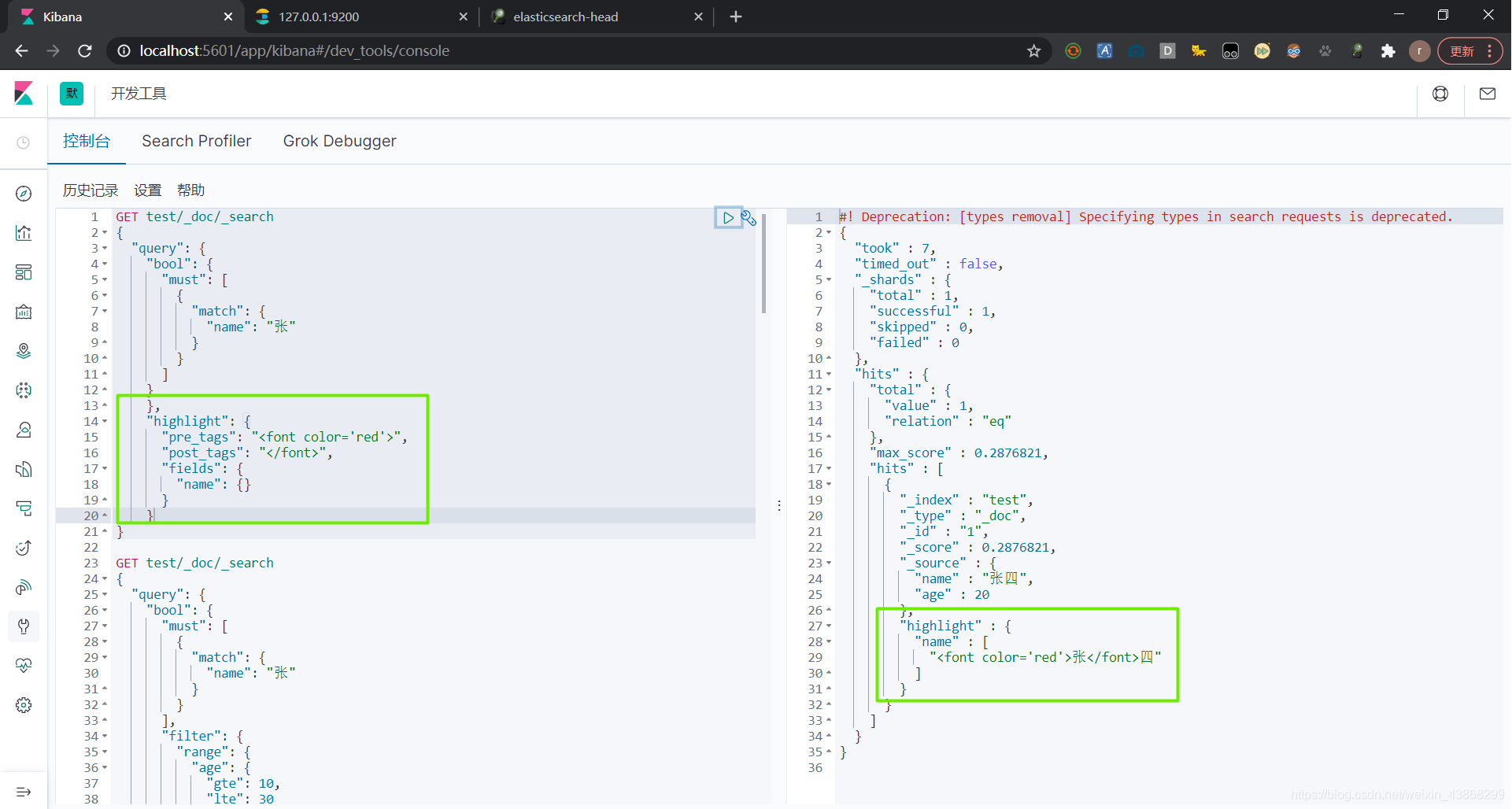
7. IK分词器
使用ES默认的分词器,会把text的字段分成一个一个汉字。当搜索一个词语时,把将词语拆成独单的汉字进行搜索,分词效果不好。所以要使用IK分词器,IK分词是一款国人开发的相对简单的中文分词器。7.1 IK分词器安装
Github地址:https://github.com/medcl/elasticsearch-analysis-ik
下载的时候需要下载和ES对应的版本,下载完成后按以下步骤完成安装:
(1)解压文件,将解压后的文件夹重命名为ik
(2)将ik文件夹拷贝到ES的plugins 目录下
(3)重新启动ES,即可加载IK分词器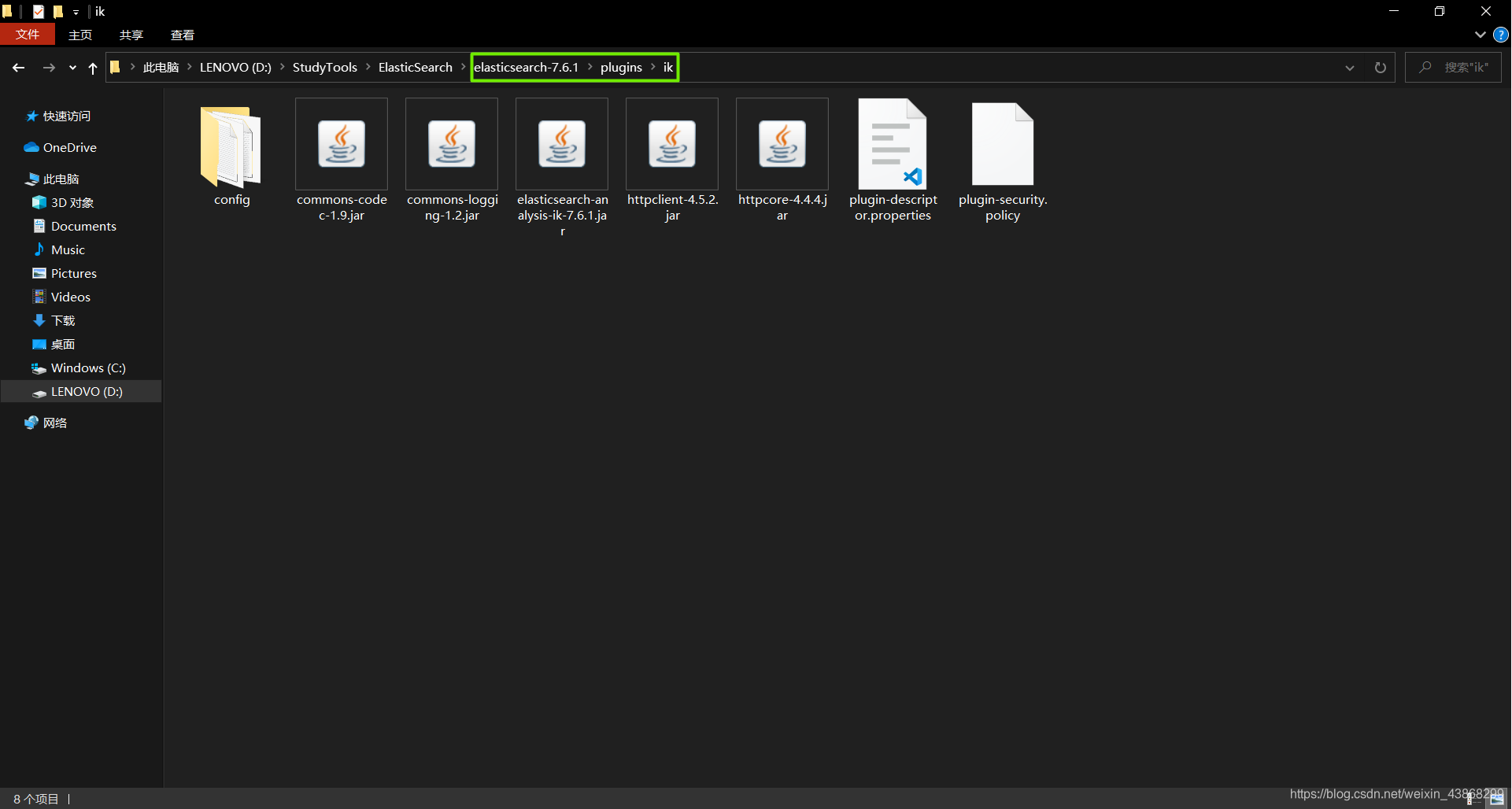
7.2 IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word
其中 ik_smart 为最少切分,ik_max_word为最细粒度切分
(1)最少切分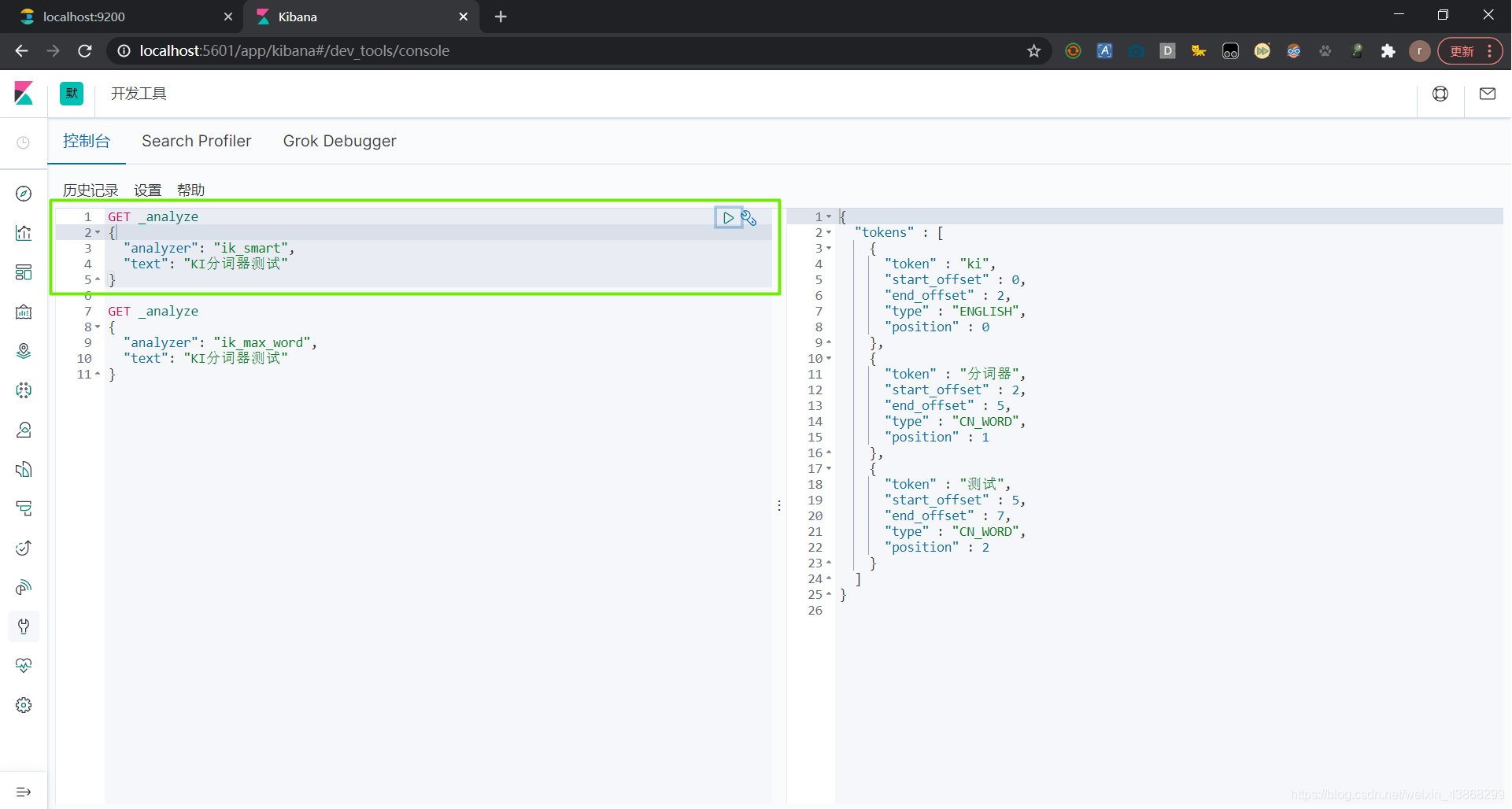
(2)最细粒度切分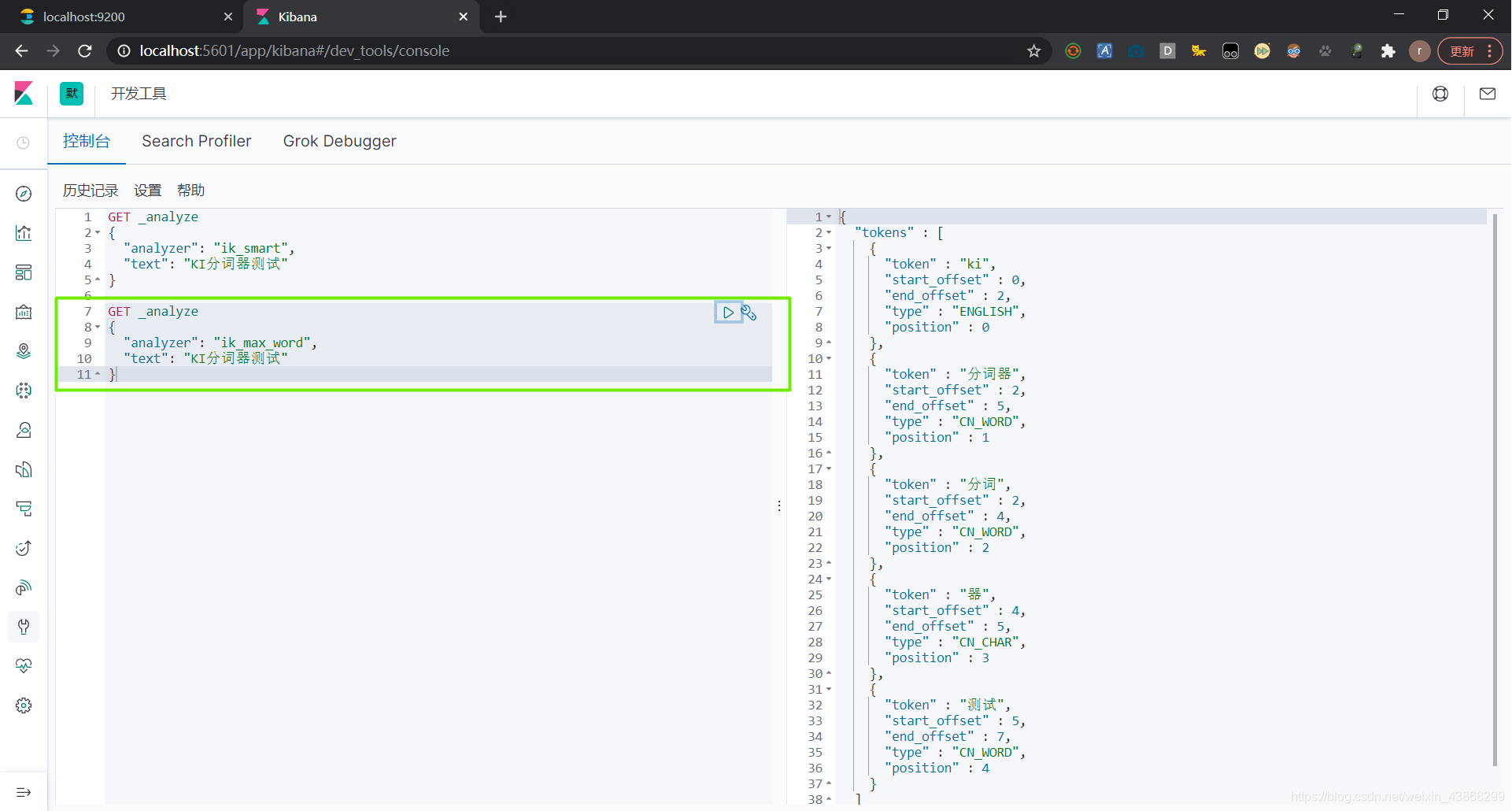
7.3 自定义词库
有时候我们搜索的词语可能是IK分词器默认词库中没有的,此时搜索该词语IK会分成单独的汉字。这时候我们可以通过配置,自定义词库。
(1)进入IK分词器的config目录,新建一个后缀名为dic的文件。用记事本打开文件,在里面添加词语,词语间要换行。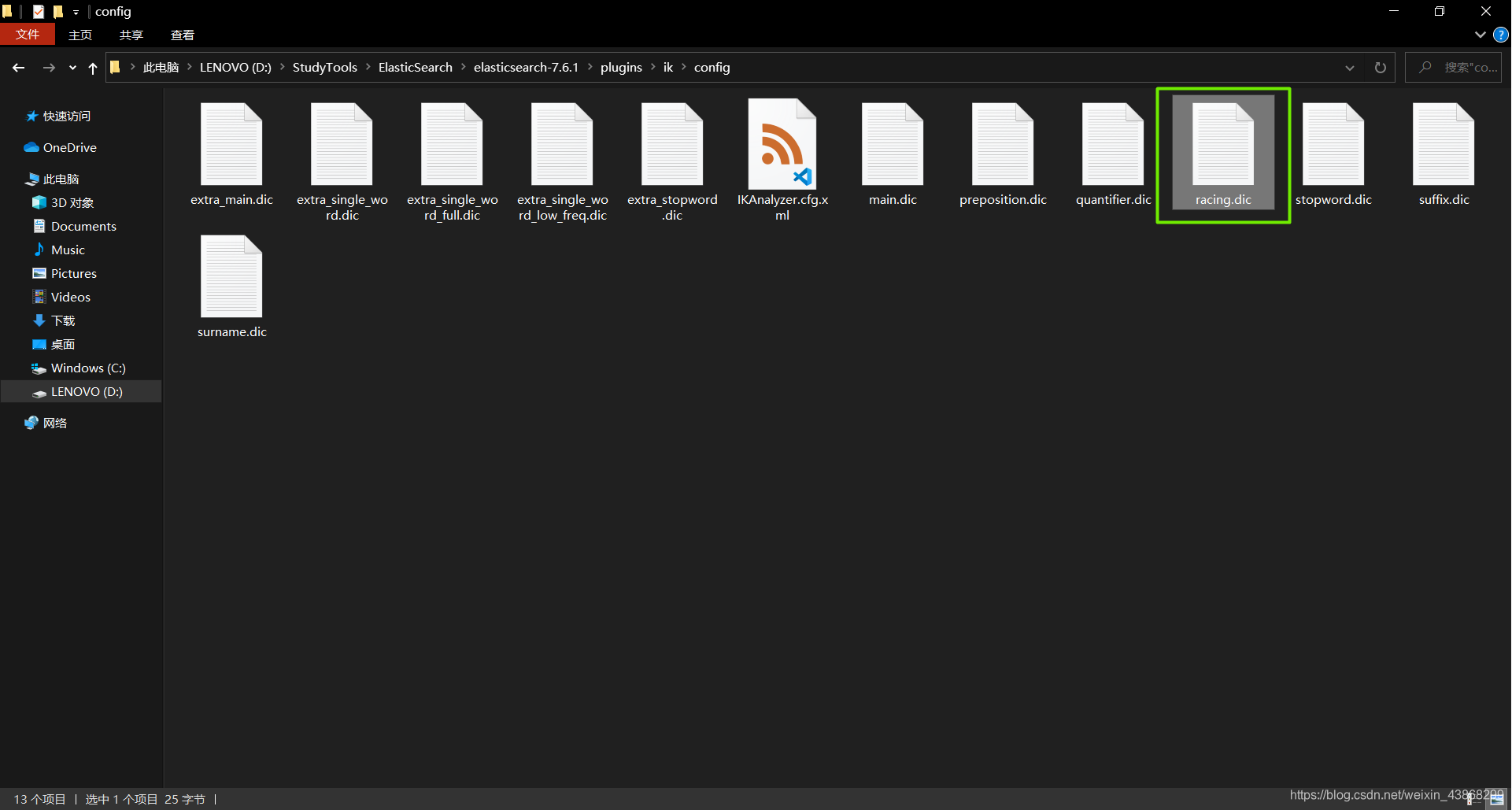
(2)打开IKAnalyzer.cfg.xml,在里面添加新建的词库文件名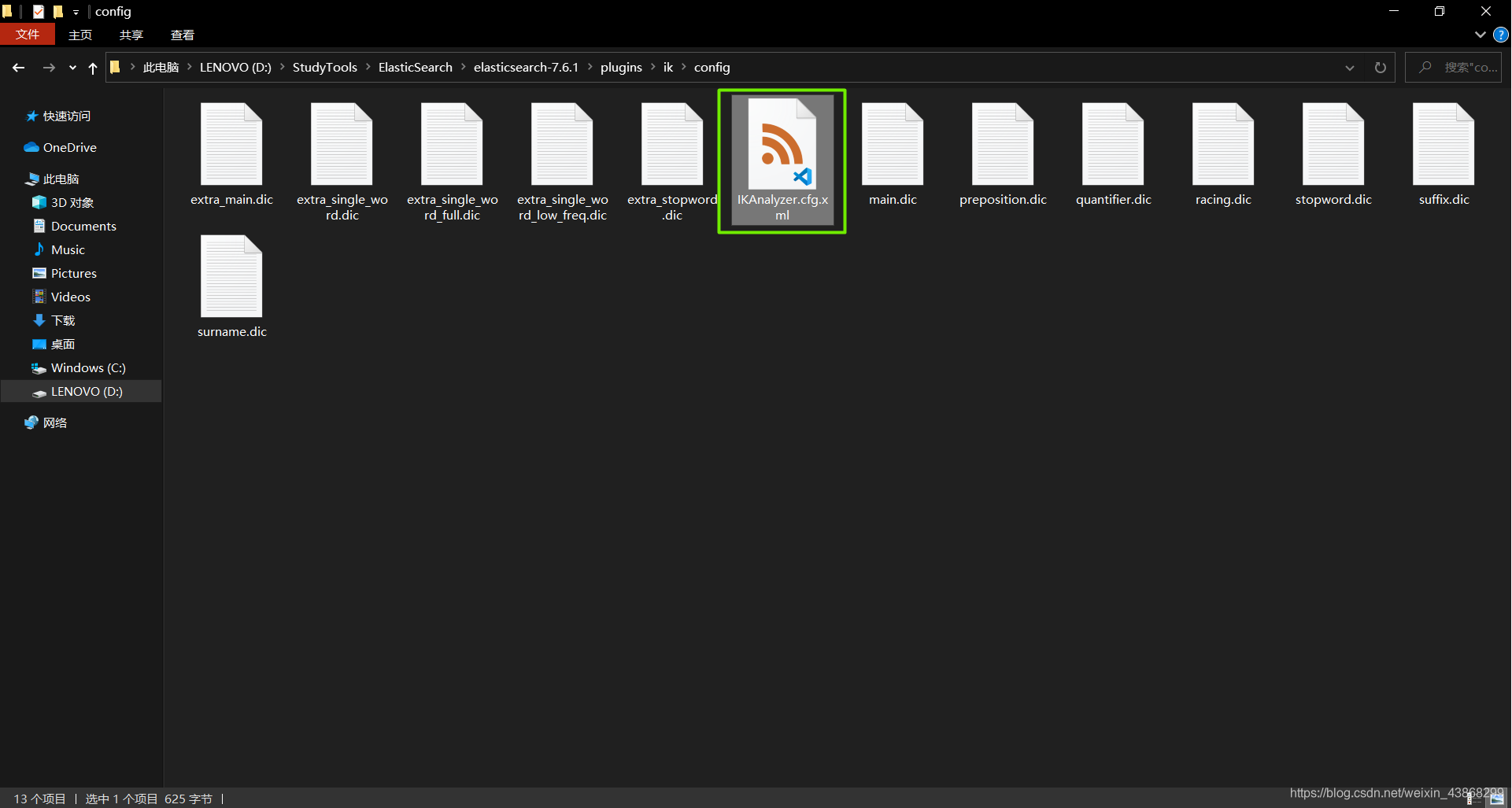
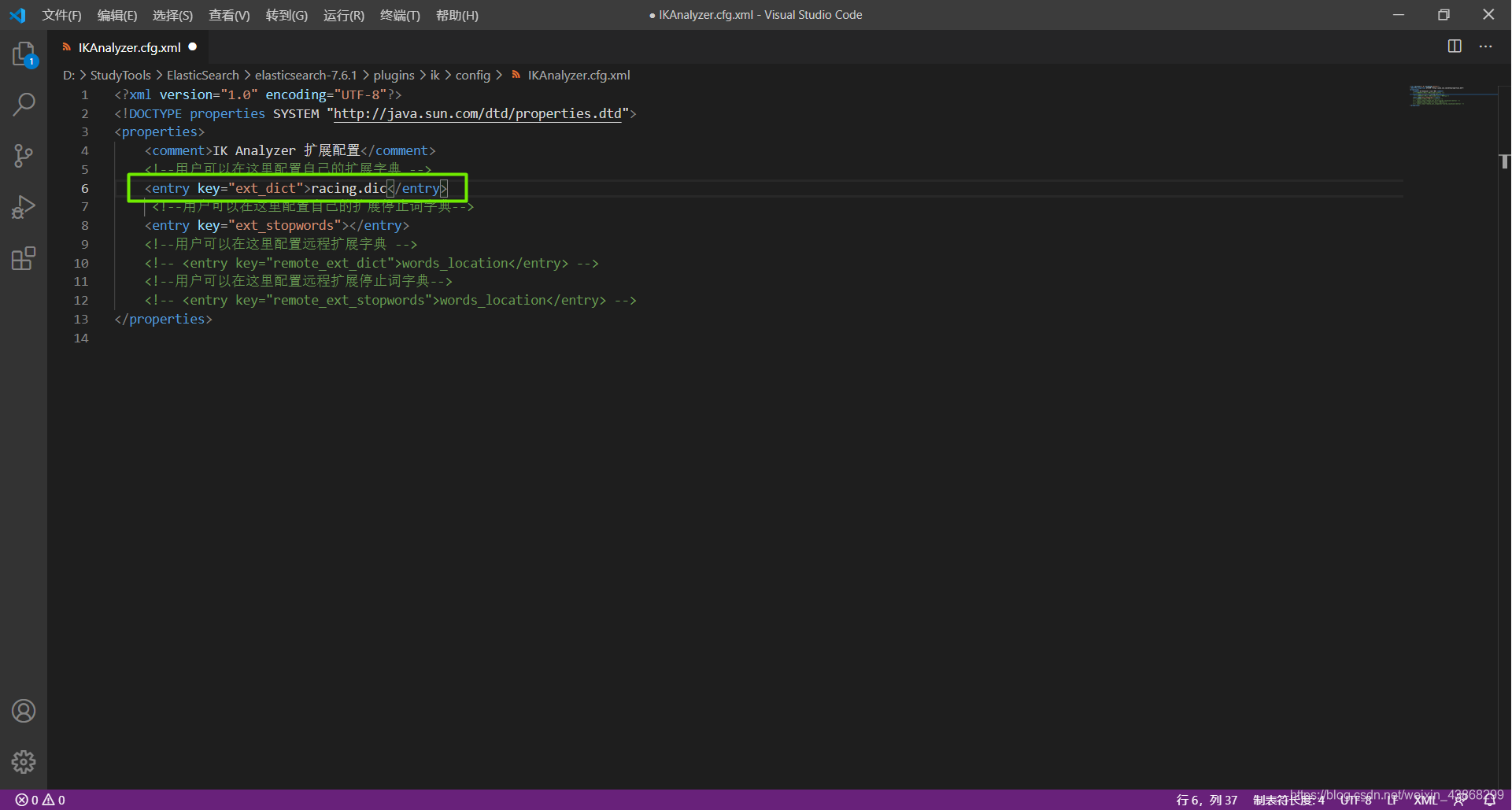
(3)重启ES,就可以使用IK分词器了